前言
ArceOS 是基于组件化思想构造、以 Rust 为主要开发语言、Unikernel 形态的操作系统。与传统操作系统的构建方式不同,组件是构成 ArceOS 的基本元素。
本实验指导从零开始,带领大家一步一步的完成 ArceOS 的构建过程。每一步都是一个小型实验,在前一步实验的基础上,以增加和扩展组件的方式,增强 ArceOS 的功能特性,最终形成一个功能相对完备的 Unikernel 操作系统。在实验过程中,我们主要采用 Rust 语言进行开发,探寻如何发挥这种新型语言的特点,实践构建操作系统的新模式和新方法。
第零章 史前时代 - 从开机到内核启动
在操作系统正式启动之前,计算机需要进行一系列的引导和初始化工作,从硬件加电开始,到 BIOS 自检,再到 BootLoader 启动,然后才会把计算机的控制权交给操作系统的内核(以下简称内核)。
本章将追踪这一过程,了解各个启动阶段所完成的工作,明确内核获得控制权必须符合的条件;然后基于 Rust 语言开发一个只包含一行代码的裸机程序,这将是我们实验的第一个内核版本,当观察到这行代码被执行时,证明我们的内核首次获得了计算机的控制权,它将从此开启自己的时代!
在此之前,我们首先需要为实验搭建开发和运行环境。
第一节 实验环境
基于 WSL2+Unbuntu22.04.2 LTS,在此基础上安装:
1、安装开发运行的依赖包
sudo apt install autoconf automake autotools-dev curl libmpc-dev libmpfr-dev \
libgmp-dev gawk build-essential bison flex texinfo gperf libtool \
patchutils bc zlib1g-dev libexpat-dev pkg-config libglib2.0-dev \
libpixman-1-dev libsdl2-dev git tmux python3 python3-pip ninja-build
2、Rust 开发环境
curl https://sh.rustup.rs -sSf | sh
cargo install cargo-binutils
3、Qemu 模拟器(RiscV64)
下载并编译针对 RiscV64 架构的模拟器:
git clone https://git.qemu.org/git/qemu.git --depth 1
cd qemu
./configure --target-list=riscv64-softmmu
make -j $(nproc)
编译后得到 build/qemu-system-riscv64,把它的路径加入当前用户环境变量文件 .bashrc,编辑 ~/.bashrc 文件(如果使用的是默认的 bash 终端),在文件的末尾加入几行:
# 请注意,/path/to 是 qemu 的父目录,应调整为实际的安装位置
export PATH=$PATH:/path/to/qemu/build
随后即可在当前终端执行 source ~/.bashrc,或者直接重启一个新的终端,使刚才的环境变量设置生效。
4、RiscV 工具集
实验中需要用到其中的 riscv64-unknown-elf-objdump 等调试工具。
sudo apt install binutils-riscv64-unknown-elf
5、FDT转换工具
用于把设备树的二进制格式 dtb 转换为可读文本的形式 dts。
sudo apt install device-tree-compiler
第二节 计算机启动过程和对内核的要求
计算机启动时,顺序引导 BIOS、BootLoader 和内核。我们的实验基于 RiscV64 架构 qemu 模拟器,它对应模拟了这一过程。

模拟器 qemu-riscv64 启动时,将会经历几个阶段:
-
程序寄存器 PC 首先被初始化为 0x1000 的地址;
-
地址 0x1000 处被 qemu 预先放置了一个 ROM,顺序执行其中包含的寥寥几行代码,PC 跳转到 0x8000_0000 地址;
-
地址 0x8000_0000 同样被 qemu 预先埋伏了 OpenSBI(后文简称 SBI),并且入口就在这个开始地址。SBI 由此处启动,进行一系列的硬件初始化工作,并提供一组基本的功能调用,为后面操作系统内核的启动准备好条件和环境;最后一步,SBI 从 M-Mode 切换到 S-Mode,并跳转到地址 0x8020_0000 继续执行;
-
地址 0x8020_0000 就是为内核准备的位置,只要我们把内核加载到此处,并且保证内核入口在开头,就能够获得计算机的控制权。
RiscV 体系结构及平台在很多方面都体现了设计上的简洁。RISC-V SBI 规范定义了平台固件应当具备的功能和服务接口,多数情况下 SBI 本身就可以代替传统上固件 BIOS/UEFI + BootLoader 的位置和作用,qemu-riscv64 模拟器同样参照模拟了这一情况,并且把 OpenSBI 集成到 qemu 工程内部。而对于 X86 等体系结构,qemu 仍是延用传统方式,即从内嵌 seabios 开始引导,经过 grub 等 BootLoader 的进一步准备,最后再启动操作系统内核。
总结一下,我们的目标是,让自己开发的内核等候在正确的位置上,并以正确的形式存在。具体来说满足以下要求:
-
内核被加载到 0x8020_0000 地址
- 这是 qemu 的职责,我们只需要指定正确的参数。
-
内核编译后的形式必须是 binary
-
Rust 编译器输出的默认执行程序格式是 ELF,这种格式需要被 ELF 加载器解析和加载。
-
显然,内核的上一级加载器 SBI 并不支持 ELF 功能,所以只能让编译出来的内核以原始 binary 形式提供。
至少目前 OpenSBI 还没有支持 ELF 的计划。但是确实存在一些其它的 BootLoader 支持这样的功能。
-
-
内核入口必须在 Image 文件的开头
- Rust 编译器默认情况下,会自己安排可执行程序文件的分段与符号布局。由于我们必须确保内核入口在最前面,所以需要通过自定义 LDS 文件的方式,控制内核 Image 文件的布局。
- 后面的实验将会用到下面的 LDS 文件 linker.lds:
OUTPUT_ARCH(riscv) BASE_ADDRESS = 0x80200000; ENTRY(_start) SECTIONS { . = BASE_ADDRESS; _skernel = .; .text : ALIGN(4K) { _stext = .; *(.text.boot) *(.text .text.*) . = ALIGN(4K); _etext = .; } ... }-
有两个地方需要注意:
-
首先是把代码区 .text 作为第一个 section,并且其中 *(.text.boot) 在 *(.text .text.*) 之前,后者是代码默认情况下所属的 section 属性。将来我们把内核入口的代码标记在 .text.boot 区域中,就可以确保它会最早被执行。
-
其次起始地址 BASE_ADDRESS 是 0x8020_0000,正是内核的运行地址,这样就可以把内核的链接地址和运行地址一致起来。如果它们不一致,基于绝对寻址方式的指令将无法正常运行,进而导致内核崩溃。将来当我们启用分页机制之后,会把这个地址固定改成对应的虚拟地址 0xffff_ffc0_8020_0000。直观看来,这个虚拟地址相对物理地址存在一个偏移量 0xffff_ffc0_0000_0000,这个偏移的名字是 PHYS_VIRT_OFFSET,将来它会在虚实地址转换中发挥重要作用,后面第二章第一节会介绍这个偏移量是如何得出的。
注:如果此时就把 BASE_ADDRESS 设置为 0xffff_ffc0_8020_0000 或者其它的什么值,似乎程序最初也可以正常运行一部分代码。主要原因是,内核启动早期的那些汇编指令,通常会被有意保持为相对寻址,即它们是位置无关指令,所以 BASE_ADDRESS 对它们不起作用。但是相对寻址的地址范围受到限制,我们不能要求内核完全采用这种寻址方式,通常只是要求在启用分页之前的指令必须是相对寻址方式。
LDS 中还有一些其它的关键信息,在后边章节再详细介绍。
完整的 linker.lds 文件见 附录A。可以在 arceos 根目录下预先建立这个文件,第四节中会用到它。
-
第三节 内核第一行代码
现在我们开始动手用 Rust 编写内核的第一个版本 v0.1。虽然它只包含一行代码,但是当我们观测到这行代码被执行时,就意味着计算机经过漫长的启动,终于把系统控制权交到我们手里,在此之后就是 ArceOS 内核的 ShowTime!
首先建立工作目录 arceos,以后我们将把它作为根目录,逐步建立组件工程,同时维护一些对编译、运行进行支持的配置和脚本。
在工作目录 arceos 中,建立第一个工程 axorigin,默认是一个基于 Rust STD 标准库的 "Hello, World!" 可执行应用程序。
mkdir arceos
cd arceos
cargo new axorigin
按上述步骤建立的应用程序,原本预期会在 Linux 上编译和运行。程序入口 main 函数并非真正的程序入口,真正的入口其实是命名为 _start 的函数,Rust 编译器会结合工具链及 Linux 内核的要求生成 _start 函数的框架,在完成一些必要的运行前准备工作后,再调用 main 函数。此外,打印输出的功能也需要通过调用 Rust STD 标准库去申请 Linux 的系统调用服务。
这种默认生成的程序显然不符合我们的需要,我们要开发的程序是操作系统而不是应用。操作系统本身就是一种基于硬件的裸机程序(baremental)。对于裸机程序,配套的 STD 库是不存在的,也无法指望 Rust 编译器为我们生成 _start 函数,我们需要自己定义 _start 函数,并通过直接管理硬件资源来满足自身及上层应用的需求。
清空 main.rs,建立内核程序入口框架。
#![no_std]
#![no_main]
#[no_mangle]
#[link_section = ".text.boot"]
unsafe extern "C" fn _start() -> ! {
core::arch::asm!(
"wfi",
options(noreturn)
)
}通过 no_std 和 no_main 告诉 Rust 编译器,程序自定义 _start 入口,不需要 main 函数和标准库支持。
同时,对 _start 标记两个属性:
-
#[link_section = ".text.boot"]:如上节所说,要求编译器把 _start 函数代码放置在 Image 文件的开头,这样当内核被加载后,入口就是第一行指令。
-
#[no_mangle]:要求编译器保持 _start 函数名称不变。这个入口符号名称在链接过程中是必须存在和可见的,所以必须阻止编译器对 _start 这个符号名称进行混淆。
_start 中当前只有唯一的一行代码 wfi,后面在 qemu 启动时,我们将监控这行代码是否被执行到。
现在尝试在工作目录 arceos 下编译 axorigin 这个工程,需要输入额外的参数:
cargo build --manifest-path axorigin/Cargo.toml \
--target riscv64gc-unknown-none-elf --target-dir ./target --release
注意:必须显式指定 riscv64gc-unknown-none-elf 这个 target,告诉 Rust 编译器我们的编译目标是 RiscV64 架构的裸机程序。
此时可能会收到下面的错误信息:
error[E0463]: can't find crate for `core`
|
= note: the `riscv64gc-unknown-none-elf` target may not be installed
= help: consider downloading the target with `rustup target add riscv64gc-unknown-none-elf`
... ...
我们可以参照提示中的命令去下载和安装 target。
但这里提供另一个解决的办法,在工作目录下直接放配置文件 rust-toolchain.toml,来定制符合我们要求的 Rust 工具链,
[toolchain]
profile = "minimal"
channel = "nightly"
components = ["rust-src", "llvm-tools-preview", "rustfmt", "clippy"]
targets = ["riscv64gc-unknown-none-elf"]
把 riscv64gc-unknown-none-elf 加入工具链的默认 target 列表;同时 channel = "nightly",因为后面会用到Rust 的一些实验特性。
再次编译,还是报错,这次的提示:
error: `#[panic_handler]` function required, but not found
根据 Rust 的设计,程序遇到不可恢复异常时将会中止运行,展开调用栈,把异常信息输出到屏幕。这个机制与底层操作系统有关,定义在 STD 标准库中。如前所述,我们没有现成的实现,所以只能自己给出定义。
增加模块文件 lang_items.rs,然后在 main.rs 中加入一行 mod lang_items; 引入该模块。
// axorigin/src/lang_items.rs
use core::panic::PanicInfo;
#[panic_handler]
fn panic(_info: &PanicInfo) -> ! {
loop {}
}现在采取最简单的方式:如果遇到不可恢复的异常,程序将会无限循环下去。后面章节实验中,我们将逐步完善这个处理机制。
再次编译,终于通过了!但是当前输出的是 ELF 格式,还不能在 qemu 中直接运行,先转为原始二进制格式:
rust-objcopy --binary-architecture=riscv64 --strip-all -O binary \
target/riscv64gc-unknown-none-elf/release/axorigin \
target/riscv64gc-unknown-none-elf/release/axorigin.bin
得到的 axorigin.bin 就是我们最初版本的内核 image 文件,先用 xxd 命令查看一下内容:
xxd -e target/riscv64gc-unknown-none-elf/release/axorigin.bin
00000000: 10500073 0000 s.P...
这个内核 image 只有 6 个字节,对照 RiscV 指令手册,最前面的四个字节正是 wfi 的指令编码。这个结果有点意外,我们在前面做的一系列考虑和具体工作,在 Rust 看来,只有那一行代码是有意义的;就连 Rust 自己要求实现的 panic_handler 最终也被它忽略了:-)。不过这个内核文件对我们下面的实验已经足够了。
终于到了运行时刻!用 qemu 运行一下:
qemu-system-riscv64 -m 128M -machine virt -bios default -nographic \
-kernel target/riscv64gc-unknown-none-elf/release/axorigin.bin \
-D qemu.log -d in_asm
成功!屏幕输出了 OpenSBI 的启动信息。但是对我们的内核来说,目前还什么事都没有干,自然不会有输出。
现在 qemu 处于等待状态,通过输入 ctrl+a x 退回到 shell。具体操作:先按 ctrl + a,再按 x 键。
查看本地即当前目录,发现多出一个 qemu.log。
执行 qemu 时的最后一行参数让 qemu 模拟器记录了它执行过的代码序列,我们只需要关注日志文件的最后:
----------------
IN:
Priv: 1; Virt: 0
0x80200000: 10500073 wfi
0x80200004: 0000 illegal
qemu 在执行过程的最后阶段,到达了预设的内核入口地址 0x8020_0000,并且执行的正是我们安排的 wfi 指令。这证明:我们之前的努力获得了成功,从此时起,计算机(模拟器)的控制权就落入我们内核的手中,后面将通过一步步的工作逐渐增强完善内核的功能。
第四节 编译与运行环境
我们成功完成了第一个内核版本的编译和运行实验,但是前面命令输入的过程太过繁琐了。下面通过建立一个 Makefile来简化输入工作。
完整的 Makefile 内容见附录 B。
把 Makefile 放到工作目录 arceos 之下,它定义了一些快捷操作:今后执行 make 就可以编译内核,或者直接执行 make run 来完成编译+运行。
尝试在工作目录下测试以下make命令的有效性。
make
make run
make clean
执行 Makefile 时可能遇到的问题:
(1) 如果在本地创建 Makefile,直接拷贝上面 Makefile 的内容,执行 make 时有可能遇到下面的错误:
Makefile:xxx: *** missing separator. Stop.
原因:recipe 必须以 TAB 进行缩进,但当拷贝时有可能拷贝进来的是空格。例如 Makefile 文件的第17行等等。
解决办法:把各种缩进统一替换为 TAB。
(2) 如果第二节中没有在 arceos 根目录下创建 linker.lds,就会报如下错误:
= note: rust-lld: error: cannot find linker script XXX/arceos/linker.lds
原因:Makefile 导出了环境变量 RUSTFLAGS,通过它通知 Rust,在链接时使用我们自定义的linker.lds 控制 Image 布局。在上一节,我们虽然漏掉了这一步骤,但是结果依然是正常的。原因大家已经看到了,当前的 Image 即 axorigin.bin 只包含一条指令,有无布局文件对结果毫无影响。今后随着代码的增加,LDS 文件将会起到关键作用。
解决办法:参照附录 A 在工作目录下建立 linker.lds。
最后看一下我们工作目录的构成情况:
.
├── axorigin
│ ├── Cargo.toml
│ └── src
│ ├── lang_items.rs
│ └── main.rs
├── LICENSE
├── linker.lds
├── Makefile
├── README.md
└── rust-toolchain.toml
第五节 Unikernel 与组件化概念
ArceOS 是基于组件化思想的,从 Unikernel 形态起步的操作系统。
在本章结束之前,我们就来讨论一下 Unikernel 与组件化这两个基本的概念。为我们后面的工作建立一个基础。
Unikernel
Unikernel 是操作系统内核设计的一种架构(或称形态),从下图对比可以看出它与其它内核架构的显著区别:

Unikernel 相对其它内核架构有三个特点:
- 单特权级:应用与内核都处于同一特权级 - 即内核态,这使得应用在访问内核时,不需要特权级的切换。
- 单地址空间:应用没有单独的地址空间,而是共享内核的地址空间,所以在运行中,也不存在应用与内核地址空间切换的问题。
- 单应用:整个操作系统有且仅有一个应用,所以没有多应用之间隔离、共享及切换的问题。
所以相对于其它内核架构,Unikernel 设计实现的复杂度更低,运行效率相对较高,但在安全隔离方面,它的能力最弱。Unikernel 有它适合的特定的应用领域和场景。
ArceOS 选择 Unikernel 作为起步,希望为将来支持其它的内核架构建立基础。本实验指导正是对应这一阶段,从零开始一步一步的构建 Unikernel 形态的操作系统。Unikernel 本身这种简化的设计,可以让我们暂时忽略那些复杂的方面,把精力集中到最核心的问题上。
组件化操作系统
组件是预构建的、可以复用的、封装特定功能的独立实体。组件的内部功能对外不可见,外部只能通过它公开的接口与之通信。
现在我们把组件化思想应用到操作系统的构建实践中,组件是构造操作系统的最基本元素(Building Block),参与操作系统构建的所有功能部件,包括底层的系统引导与硬件封装,中层的各种子系统核心功能,上层的驱动以及服务,甚至内嵌到 Unikernel 中的应用,全部都是组件。
构建操作系统的过程大致可以分为两步:第一步是基于经验与实践,不断提炼组件,以建立基本的组件仓库;第二步是从仓库中选择适当的组件以适当的方式进行组合,形成目标操作系统。在我们的实验中,这两步是不断重复,反复迭代的过程。
在 Rust 开发中,组件 $\approx$ crate,在之后的内核开发实验中,将以构建 crate 的方式来构建组件,并将主要通过 dependencies+features 的方式组合组件,构造目标系统。
当本实验指导书的所有实验完成后,会形成如下图所示的组件化的操作系统:

本章总结
这一章我们学习了从计算机启动到进入内核的过程;建立了实验环境,并且实现了一个仅包含一行代码的最小内核。然后我们了解了 Unikernel 和组件化的基本概念,为后面的工作建立了基础。
从下一章开始,我们将会以组件化的方式,逐步的扩展这个 Unikernel 内核的功能与特性。
第一章 Hello, ArceOS! - 内核启动和组件诞生
通过前面一章的工作,我们已经构建了只包含一条指令的内核。这一章将会以此为起点,让内核完成启动和初始化工作,并且以向屏幕输出信息的方式宣告"内核启动成功"。在此基础上,我们将按照分层原则,把内核分裂为两个组件:管理硬件的基础组件和反映业务逻辑的应用组件,再把这两个组件重新组合为内核。这个分裂又重组的工作,当前看来或许无聊可笑,但在将来会逐渐体现出它的意义,这一步将是以组件化方式构造操作系统内核的开始,后面我们会以重用性为目标,提炼总结组件形成仓库,并不断寻找更好的组件管理和组合方式。
下面,先来看一下在最初的启动阶段,内核需要完成哪些工作。
第一节 内核启动
各种操作系统内核在最初启动时,通常都需要完成以下的几项工作:
- 清零BSS区域
- 保存一些必要的信息
- 启用内存分页
- 设置中断/异常向量表
- 建立栈以支持函数调用
- ... ...
每一项初始工作都具有特定的作用,并且与后续的工作相关。
这一节作为起步阶段,首先完成第 1 步和第 5 步,其它工作项暂时忽略,我们将在扩展对应的内核功能时,再回头进行补充。
第1步 - 清零 BSS 区域
BSS 是构成内核 Image 的一个特殊的数据区,编译器会把程序中未显式初始化的全局变量放到这个区域,这些全局变量默认值都应当是零。但是编译器本身并不执行 BSS 清零工作,这个通常是 ELF 加载器的工作。对于我们正在开发的内核,既然没有其它程序替我们完成,那就只好自己对 BSS 区域清零。
第5步 - 建立栈以支持函数调用
建立栈支持函数调用之后,我们就可以脱离晦涩的汇编语言,进入 Rust 的编程世界,利用 Rust 高级语言提供的各种先进特性实现内核功能。作为 Unikernel 内核,应用与内核都会使用这同一个栈,所以我们直接预分配 256K 的大栈空间,减少将来因栈溢出而带来的困扰。
现在我们就在 axorigin 中引入引导模块 boot,实现上面的两步:
// axorigin/src/boot.rs
#[no_mangle]
#[link_section = ".text.boot"]
unsafe extern "C" fn _start() -> ! {
// a0 = hartid
// a1 = dtb
core::arch::asm!("
la a3, _sbss
la a4, _ebss
ble a4, a3, 2f
1:
sd zero, (a3)
add a3, a3, 8
blt a3, a4, 1b
2:
la sp, boot_stack_top // setup boot stack
la a2, {entry}
jalr a2 // call rust_entry(hartid, dtb)
j .",
entry = sym super::rust_entry,
options(noreturn),
)
}从 _start 入口 开始,上面这段汇编代码分为三个部分:
第 8~15 行:实现了 BSS 清零,BSS 区域的起止地址是 _sbss 和 _ebss,都定义在 linker.lds 中的 .bss 段中,符号可以被汇编直接引用。

第 17 行:初始化寄存器 sp,指向栈空间的最高地址 - 即栈底位置 boot_stack_top,该符号同样是定义在 linker.lds 文件的 .bss 中。如上图,在 .bss 段的开头,预留了 256K 的空间,并且 boot_stack_top 是空间的最高地址。另外,需要注意的是,这段栈空间并不包含在由 _sbss 和 _ebss 标记的范围内,因为栈不需要预先初始化。
第 25 和 26 行:在栈准备好的情况下,首次进入 Rust 函数 rust_entry。
先通过 la 指令取得 rust_entry 的入口地址,然后通过 jalr 调用该地址。按照 RiscV 规范,a0 到 a7 寄存器分别作为函数调用的前 8 个参数,当下只有 a0 和 a1 是有效的。这两个寄存器由上一级引导程序 SBI 设置,a0 保存了 HartID,也就是当前 cpu 核的硬件 ID;a1 则指向了一块内存区,其中保存的是描述底层平台硬件信息的设备树,即 dtb。
从上面的那段汇编代码可以看出,内核从启动到调用 Rust 入口函数过程中,没有使用过 a0 和 a1。如果在这个过程中必须使用它们,就必须先暂存它们的值,然后在调用 rust_entry 前恢复回来。这个就是本节开始时,提到的第 2 项任务,将来会看到这种处理的必要性。
最后,看看函数 rust_entry 的定义:
// axorigin/src/main.rs
#![no_std]
#![no_main]
#![feature(asm_const)]
mod lang_items;
mod boot;
unsafe extern "C" fn rust_entry(_hartid: usize, _dtb: usize) {
core::arch::asm!(
"wfi",
options(noreturn)
)
}目前 rust_entry 还干不了任何事,所以仍然调用 wfi 指令。注意它的两个参数 _hartid 和 _dtb,就是通过 a0 和 a1 寄存器传入的,暂时还用不到它们,但在将来它们会发挥重要作用。
用 make run 编译并执行,然后打开 qemu.log 并跳到末尾,查看从 0x80200000 开始直到 0x80200034 这段范围执行的指令序列,确认它们与我们编写的汇编代码等效。
在 qemu.log 中看到的指令,在形式上与我们编写的汇编指令有一点出入。 主要是因为我们用了一些伪指令,大家可通过 RiscV ASM 手册,查阅这些伪指令与实际指令的对应关系。
第二节 SBI 功能调用
到目前为止,我们还看不到内核的输出信息,只能通过查看 qemu 跟踪日志,确认工作成果。现在是实现打印输出的时候了!
有两个办法可以让内核支持 console,一是通过管理 Uart 串口设备进行输出,二是直接调用 OpenSBI 提供的功能。前一个方式需要自己实现驱动,但目前我们连最基础的内存管理都未能完成,缺乏实现驱动的条件;所以决定采用第二个办法。
前面一章提到,OpenSBI 提供了一系列功能调用,可以通过调用号去请求 SBI 为我们完成部分工作。查阅 OpenSBI 文档,发现功能调用 console_putchar 具有打印输出一个字符的能力,正可以作为输出功能的基础。然后从 crate.io 中,我们找到了 sbi-rt 这个现成的库,它封装了对 sbi 功能调用的各种方法。现在就使用它来实现 console 模块。
// axorigin/src/console.rs
pub fn putchar(c: u8) {
#[allow(deprecated)]
sbi_rt::legacy::console_putchar(c as usize);
}
pub fn write_bytes(bytes: &[u8]) {
for c in bytes {
putchar(*c);
}
}在 Cargo.toml 中,引入对 sbi-rt 的依赖。
// axorigin/Cargo.toml
[dependencies]
sbi-rt = { version = "0.0.2", features = ["legacy"] }
把 mod console 引入 main.rs,把 wfi 指令替换为调用字符串输出。
mod console;
unsafe extern "C" fn rust_entry(_hartid: usize, _dtb: usize) {
console::write_bytes(b"\nHello, ArceOS!\n");
}通过 make run 运行,终于在屏幕上看到了输出 “Hello, ArceOS!”。
仅仅支持输出字符串不方便,下面来进一步支持类似 print 的变参输出方式。
首先定义一个代表 Console 的全局变量,实现 Write 这个 Trait:
// axorigin/src/console.rs
use core::fmt::{Write, Error};
struct Console;
impl Write for Console {
fn write_str(&mut self, s: &str) -> Result<(), Error> {
write_bytes(s.as_bytes());
Ok(())
}
}
pub fn __print_impl(args: core::fmt::Arguments) {
Console.write_fmt(args).unwrap();
}当我们对 Console 调用 write_fmt(...) 时,Rust 库会帮助处理变参,我们只需要实现 write_str(...) 这个 Trait 的方法就可以了。
然后,提供两个宏定义 ax_print! 和 ax_println! 封装输出功能:
// axorigin/src/console.rs
#[macro_export]
macro_rules! ax_print {
($($arg:tt)*) => {
$crate::console::__print_impl(format_args!($($arg)*));
}
}
#[macro_export]
macro_rules! ax_println {
() => { $crate::print!("\n") };
($($arg:tt)*) => {
$crate::console::__print_impl(format_args!("{}\n", format_args!($($arg)*)));
}
}最后,在 axorigin 中调用 ax_println! 宏测试一下,删除 console::write_bytes(...) 那一行,替换为 ax_println! 输出:
// axorigin/src/main.rs
unsafe extern "C" fn rust_entry(_hartid: usize, _dtb: usize) {
let version = 1;
ax_println!("\nHello, ArceOS!");
ax_println!("version: [{}]", version);
}通过 make run 编译运行,看到作为变参的 version 信息输出。显示如下:
Hello, ArceOS! version: [1]
目前只能支持 Rust 基本类型,等下一章支持动态内存分配之后,我们再进一步测试对复杂集合类型的输出功能。
第三节 应用组件与硬件抽象组件
从本节开始,我们将开启组件化构造操作系统内核的旅程。
与传统构造内核的方法不同,组件化构造内核包括两个部分:一是建立一个组件仓库,其中的组件都具有高度的功能内聚性和可复用性;二是建立一种管理、选择和组合组件的方法与机制。在二者的基础上,我们就可以根据需要,基于组合组件的方式来构建内核。

接下来,我们就对应上面所述的两个部分,分两个步骤进行实验。
第一步:对当前版本的单一内核进行分解,形成最初的组件仓库。

当前内核虽然是 Unikernel 形态,按照功能仍然可以分成系统和应用两层。
- 系统层:迄今为止,我们进行的大部分工作都可以归纳到系统层,大多是针对硬件平台的操作,包括启动模块 boot,控制台模块 console 等等。这些模块的共同特点:对外提供一个抽象的硬件操作接口,内部则封装了针对 RiscV 体系结构和具体硬件的操作。我们希望把上述接口明确固定下来,形成一个稳定的硬件抽象层 Hardware Abstract Layer(简称 HAL)。以 HAL 分界,实现上下层组件的解耦,方便我们将来对其它体系结构及平台的支持工作。
- 应用层:目前应用层的工作仅仅是调用 console,向屏幕输出 Hello 信息。我们要把 rust_entry 框架从应用中分离出去,因为那些属于系统层的功能。
基于这样的层次划分,我们就分解出最初的两个组件 axhal 和 axorigin。其中,axorigin 继承了原始内核工程的名字,但它的身份已经降级成为一个应用组件,将来必须与 axhal 等系统组件配合来构成完整的 Unikernel 系统。
-
axhal 组件
-
封装系统层的模块,从外部形式看,它是一个 lib 形式的 crate。但是从启动角度,由于它的 boot 模块包含了内核的 _start 入口,其实是首先运行的,然后才会去启动应用组件。看一下这个 crate 的根模块 lib.rs 和 Cargo.toml:
// axhal/src/lib.rs #![no_std] #![no_main] mod lang_items; mod boot; pub mod console; unsafe extern "C" fn rust_entry(_hartid: usize, _dtb: usize) { extern "C" { fn main(hartid: usize, dtb: usize); } main(_hartid, _dtb); } // axhal/Cargo.toml [package] name = "axhal" version = "0.1.0" edition = "2021" See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html [dependencies] sbi-rt = { version = "0.0.2", features = ["legacy"] } -
组件 axhal 继承了上一版本内核几乎所有的模块,以及 rust_entry 框架,只是把直接调用 console 进行打印的代码,替换成一个外部函数 main,这个 main 函数就是新的应用组件 axorigin 的主函数,其中包含 console 打印。这里可能会产生一个疑问,为什么需要通过 extern ABI 这种外部函数的形式去调用?而不能以引入依赖 crate 的方式去调用?后面会说明这一原因。
-
-
axorigin 组件
-
前面提到了,这个组件只是继承了原来内核工程的名字,目前已经退化成一个应用组件。与组件 axhal 相应的,从外部看,axorigin 具有 main.rs 根模块,形式上就是一个 binary crate;但是它自身是无法运行的,需要等待 axhal 组件启动它。
-
来看一下 axorigin 当前的 main.rs 实现:
-
#![no_std] #![no_main] use axhal::ax_println; #[no_mangle] pub fn main(_hartid: usize, _dtb: usize) { let version = 1; ax_println!("\nHello, ArceOS!"); ax_println!("version: [{}]", version); } -
主体就是一个 main 函数,正对应 axhal 组件在最后阶段要调用的函数,main 是所有应用类型组件的入口。
这个 main,与我们基于 Linux/Windows 平台进行应用编程时写的 main,其实并无关系,上面
#[no_main]已经说明了这一点。这里起这个名字,只是为了适应编程习惯。 -
-
目前,应用组件 axorigin 在 main 函数中要实现的逻辑非常简单,但是它为我们建立了基本的 Unikernel 应用框架;将来在开发 Unikernel 应用时,只需要按此方式创建一个应用组件,并在 main 函数中实现业务逻辑即可。应用逻辑开发与系统功能的实现从此分离。
-
-
第二步:对现有的两个组件进行组合,形成可以运行的内核。
既然两个组件都是 Rust crate 的形式,最简单的组合方式,自然就是利用 Cargo 工具提供的 denpendencies 依赖机制进行连接组合。
来看 axorigin 的 Cargo.toml:
[package]
name = "axorigin"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
axhal = { path = "../axhal" }
建立应用组件 axorigin 对 axhal 的依赖之后,Cargo 就可以自动为我们组合组件构造出内核。
用 git show --stat 比较当前基于组件化的版本与上一版本在代码方面的变化:
axorigin/Cargo.toml | 2 +-
axorigin/src/main.rs | 8 +++-----
{axorigin => axhal}/src/boot.rs | 0
{axorigin => axhal}/src/console.rs | 0
{axorigin => axhal}/src/lang_items.rs | 0
axhal/Cargo.toml | 9 +++++++++
axhal/src/lib.rs | 13 +++++++++++++
7 files changed, 26 insertions(+), 6 deletions(-)
运行 make run 测试,屏幕输出没有变化。
Hello, ArceOS! version: [1]
但是我们已经步入了组件化构造内核的进程中。
在本节结束之前,解释一下之前的问题:为什么在启动过程中,组件 axhal 必须通过 extern ABI 的方式调用组件 axorigin 的 main 函数。

从图中可以看到,两个组件之间存在相互调用的关系,启动过程中 axhal 调用 axorigin 的 main 函数;运行过程中 axorigin 作为应用需要调用系统组件 axhal 的各种功能。既然 axorigin 已经通过 Cargo.toml 对 axhal 建立了依赖,那么另一个方向的依赖就不成立了,否则就会导致循环依赖。因此只好在启动过程中,采用 extern ABI 的方式调用 main 函数。
在我们将来构造内核的实验中,循环依赖将会是一个比较麻烦的问题。在第三章里,将会引入一个特殊的组件 crate_interface 专门用于处理循环依赖,本质上它仍然是基于 extern ABI,但是基于该组件提供了一种 Rusty 风格的调用方式,这样来做,代码的可读性更好,同时可以有效减少编程出错的概率。
第四节 组件测试和模块测试
Rust 工具链本身对测试的支持很方便,下面将基于这一有利条件,对内核的组件和模块进行功能测试验证。组件测试相当于 crate 级的测试,直接在 crate 根目录下建立 tests 模块,对组件进行基于公开接口的黑盒测试;模块测试对应于单元测试,在模块内建立子模块tests,对模块的内部方法进行白盒测试。在 Makefile 中,预留了一个test 命令入口,用于启动上述测试。
我们需要注意一个容易忽略的事实,通过 make run 编译并运行内核,与通过 make test 编译并执行测试,这二者的编译和运行环境是截然不同的,前者的编译目标是 RiscV64 体系结构,并通过 qemu-riscv64 模拟器运行;后者则是针对本地的 x86_64 体系结构,在本地 Linux 上作为应用直接运行(Linux on x86_64 这应该是我们大多数人的本地开发环境)。因此,通过 Rust 工具链进行测试是有局限的,测试的功能与实际将要运行的功能可能存在差异,测试时还有可能需要一些 dummy 测试桩的辅助。我们需要清醒的保持这一认识,避免在后面的实验开发和测试中陷入困惑。
下面对现有的工程项目进行一些改造,满足测试的需要:
-
Makefile 中 test 命令
调用
cargo test启动测试:ifeq ($(filter $(MAKECMDGOALS),test),) # not run `cargo test` RUSTFLAGS := -C link-arg=-T$(LD_SCRIPT) -C link-arg=-no-pie export RUSTFLAGS endif test: cargo test --workspace --exclude "axorigin" -- --nocapture测试针对整个工程 workspace 下包含的所有组件,只是排除 axorigin 应用本身。我们希望测试用例中能够通过 println! 直接输出信息到屏幕,所以指定了
--nocapture参数。特别需要注意的是上面的 1~4 行,环境变量
RUSTFLAGS不能出现在make test的过程中,原因前面已经说了,测试时是基于 x86_64 的体系结构,这个环境变量却要求使用面向 RiscV64 的 linker.lds 链接脚本和参数。如果不注意这一点,就会出现如下的错误:= note: /usr/bin/ld: cannot represent machine `riscv' collect2: error: ld returned 1 exit status error: could not compile `axhal` (lib test) due to previous errorx86 工具链的链接器在解析 linker.lds 第一行时就发现错误,它不能识别
OUTPUT_ARCH(riscv),直接报错退出了。 -
工程 Workspace 级的 Cargo.toml
[workspace] resolver = "2" members = [ "axorigin", "axhal", ] [profile.release] lto = true以后增加新组件时,需要扩展 members 列表。
-
改造 axhal 组件的代码组织结构
组件 axhal 负责屏蔽体系结构的差异,所以它对
make test所要求的另类环境最为敏感。首先改造 crate 的 lib.rs:
// axhal/src/lib.rs #![no_std] #[cfg(target_arch = "riscv64")] mod riscv64; #[cfg(target_arch = "riscv64")] pub use self::riscv64::*; // axhal/src/riscv64.rs mod lang_items; mod boot; pub mod console; unsafe extern "C" fn rust_entry(_hartid: usize, _dtb: usize) { extern "C" { fn main(hartid: usize, dtb: usize); } main(_hartid, _dtb); }原来 lib.rs 只是针对 RriscV64 的实现,现在下移到 riscv64.rs 模块文件中;相应的,lang_items.rs、boot.rs和 console.rs 三个文件,也移到到目录 riscv64 下。这样只有当目标体系结构是 RriscV64 时,才会引用这些实现,因而执行测试时不会编译它们。
改造 axhal 的 Cargo.toml:
[target.'cfg(target_arch = "riscv64")'.dependencies] sbi-rt = { version = "0.0.2", features = ["legacy"] }把 [dependencies] 改成带体系结构条件的形式,避免在执行测试时引入 sbi-rt 这个无效引用。
用 git show --stat 看一下改造后的情况:
Cargo.toml | 10 ++++++++++
Makefile | 7 ++++++-
axhal/Cargo.toml | 2 +-
axhal/src/lib.rs | 15 ++++-----------
axhal/src/riscv64.rs | 10 ++++++++++
axhal/src/{ => riscv64}/boot.rs | 0
axhal/src/{ => riscv64}/console.rs | 0
axhal/src/{ => riscv64}/lang_items.rs | 0
8 files changed, 31 insertions(+), 13 deletions(-)
分别执行 make run 和 make test,验证我们的成果。
前者的输出没有变化,而执行后者时,显示如下:
cargo test --workspace --exclude "axorigin" -- --nocapture Compiling axhal v0.1.0 (/home/cloud/gitStudy/arceos_tutorial/axhal) Finished test [unoptimized + debuginfo] target(s) in 0.20s Running unittests src/lib.rs (target/debug/deps/axhal-0770fa3f3cc1ea75)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests axhal
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
目前还没有写任何测试用例,测试框架只是空转一次。
下节开始,我们将使用测试用例来驱动内核的开发。
第五节 全局配置与同步支持
在本章的最后,增加几个常用工具组件,为后续的实验工作做一个准备。
-
全局配置组件 axconfig
创建组件 axconfig,主要用来提供全局的配置参数和一些常用的工具函数,它的 lib.rs 就如这样:
// axconfig/src/lib.rs #![no_std] pub const PAGE_SHIFT: usize = 12; pub const PAGE_SIZE: usize = 1 << PAGE_SHIFT; pub const PHYS_VIRT_OFFSET: usize = 0xffff_ffc0_0000_0000; pub const ASPACE_BITS: usize = 39; pub const SIZE_1G: usize = 0x4000_0000; pub const SIZE_2M: usize = 0x20_0000; #[inline] pub const fn align_up(val: usize, align: usize) -> usize { (val + align - 1) & !(align - 1) } #[inline] pub const fn align_down(val: usize, align: usize) -> usize { (val) & !(align - 1) } #[inline] pub const fn align_offset(addr: usize, align: usize) -> usize { addr & (align - 1) } #[inline] pub const fn is_aligned(addr: usize, align: usize) -> bool { align_offset(addr, align) == 0 } #[inline] pub const fn phys_pfn(pa: usize) -> usize { pa >> PAGE_SHIFT }在我们的实验中,页面 Page 采用最常见的 4096 字节。同时提供一组与对齐相关的工具函数。
后面我们会陆续加入更多的配置参数和工具函数。
可以在真正实现 align 相关函数之前,先写好测试用例,以测试驱动的方式开发该组件功能:
// axconfig/tests/test_align.rs use axconfig::{align_up, align_down, PAGE_SIZE}; #[test] fn test_align_up() { assert_eq!(align_up(23, 16), 32); assert_eq!(align_up(4095, PAGE_SIZE), PAGE_SIZE); assert_eq!(align_up(4096, PAGE_SIZE), PAGE_SIZE); assert_eq!(align_up(4097, PAGE_SIZE), 2*PAGE_SIZE); } #[test] fn test_align_down() { assert_eq!(align_down(23, 16), 16); assert_eq!(align_down(4095, PAGE_SIZE), 0); assert_eq!(align_down(4096, PAGE_SIZE), PAGE_SIZE); assert_eq!(align_down(4097, PAGE_SIZE), PAGE_SIZE); }上面是组件级的测试用例,直接放在 axconfig/tests 目录下,用于对组件公开接口的测试。
执行
make test,显示测试成功:Running tests/test_align.rs (target/debug/deps/test_align-087b60d36f414a97)
running 2 tests test test_align_down ... ok test test_align_up ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
-
自旋锁 SpinRaw
在真正启动多任务和启用中断之前,内核一直处于纯粹的单线程执行状态,没有任何并发,自然也没有同步的问题,当前对于全局变量的修改是安全的。但是 Rust 不清楚这一点,所以我们需要先实现一个最初版本的自旋锁 SpinRaw,用它包装 mutable 全局变量,假装已经有了同步保护,但实际上它目前只是个空壳。
创建组件 spinlock,在模块 raw.rs 中实现 SpinRaw 类型。
// spinlock/src/lib.rs #![no_std] mod raw; pub use raw::{SpinRaw, SpinRawGuard}; // spinlock/src/raw.rs use core::cell::UnsafeCell; use core::ops::{Deref, DerefMut}; pub struct SpinRaw<T> { data: UnsafeCell<T>, } pub struct SpinRawGuard<T> { data: *mut T, } unsafe impl<T> Sync for SpinRaw<T> {} unsafe impl<T> Send for SpinRaw<T> {} impl<T> SpinRaw<T> { #[inline(always)] pub const fn new(data: T) -> Self { Self { data: UnsafeCell::new(data), } } #[inline(always)] pub fn lock(&self) -> SpinRawGuard<T> { SpinRawGuard { data: unsafe { &mut *self.data.get() }, } } }按照 Rust 要求,标记 SpinRaw 具有 Send 和 Sync 的标记 trait。
实现 lock 方法返回 SpinRawGuard,假装这个 guard 持有了锁,guard 是 RAII 的模式,当它释放即执行 drop 方法时自动解锁。目前没有实际解锁动作,直接忽略对 Drop trait 的实现。
然后我们为 guard 实现 Deref 和 DerefMut 两个 Trait,把它作为智能指针以方便直接访问 SpinRaw 包装变量的方法。
// spinlock/src/raw.rs impl<T> Deref for SpinRawGuard<T> { type Target = T; #[inline(always)] fn deref(&self) -> &T { unsafe { &*self.data } } } impl<T> DerefMut for SpinRawGuard<T> { #[inline(always)] fn deref_mut(&mut self) -> &mut T { unsafe { &mut *self.data } } }编写测试用例,验证对外公开的组件接口功能:
// spinlock/tests/test_raw.rs use spinlock::SpinRaw; struct Inner { val: usize, } impl Inner { const fn new() -> Self { Self { val: 0 } } fn set(&mut self, v: usize) { self.val = v; } fn get(&self) -> usize { self.val } } static SPIN: SpinRaw<Inner> = SpinRaw::new(Inner::new()); #[test] fn test_lock() { SPIN.lock().set(1); assert_eq!(SPIN.lock().get(), 1); }执行
make test测试,显示:Running tests/test_raw.rs (target/debug/deps/test_raw-70e610058ffa9914)
running 1 test test test_lock ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
-
BootOnceCell
类似于上面情况,有些全局变量虽然需要设置,但是仅需要一次,之后就一直是只读状态,这属于延迟初始化的一种。
例如下一章马上要涉及的早期页表根目录 KERNEL_PAGE_TABLE,这个全局变量只需要初始化一次,但是负责初始化的是一个函数,没法在定义时直接调用,只能延迟初始化。那么就可以借助这个 BootOnceCell 来封装 KERNEL_PAGE_TABLE。
创建组件 axsync,在模块 bootcell.rs 中实现类型 BootOnceCell。
// axsync/src/lib.rs #![no_std] mod bootcell; pub use bootcell::BootOnceCell; // axsync/src/bootcell.rs use core::cell::OnceCell; pub struct BootOnceCell<T> { inner: OnceCell<T>, } impl<T> BootOnceCell<T> { pub const fn new() -> Self { Self { inner: OnceCell::new() } } pub fn init(&self, val: T) { let _ = self.inner.set(val); } pub fn get(&self) -> &T { self.inner.get().unwrap() } pub fn is_init(&self) -> bool { self.inner.get().is_some() } } unsafe impl<T> Sync for BootOnceCell<T> {}注意两点:
- 我们以 Rust 库提供的 OnceCell 为基础进行实现,比较简便。
- 顾名思义,BootOnceCell 的那一次初始化调用必须在 Boot 阶段,即单线程环境下完成,之后就变成了只读变量,这样再启用多线程也没有问题。但如果初始化操作是在启用多线程或中断之后再进行,就是不安全的。一定注意这个调用时机。
BootOnceCell 是对 lazy_static 的替代实现。
对应的测试用例如下:
// axsync/tests/test_bootcell.rs use axsync::BootOnceCell; static TEST: BootOnceCell<usize> = BootOnceCell::new(); #[test] fn test_bootcell() { assert!(!TEST.is_init()); TEST.init(101); assert_eq!(TEST.get(), &101); assert!(TEST.is_init()); }执行
make test测试,显示:Running tests/test_bootcell.rs (target/debug/deps/test_bootcell-3224367d8bbd079d)
running 1 test test test_bootcell ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
本章总结
这一章我们完成了内核的初始化,并且向屏幕输出了信息。在此基础上,我们建立了最早的组件仓库和组合组件的方式,现在有了分离的应用组件 axorigin 和第一个系统级组件 axhal,axhal 用于对底层体系结构和硬件的差异进行屏蔽。我们还在工程中引入了对组件和模块测试的支持,并为下一步内核的开发准备了几个最基础的组件。
下一章,我们将会针对操作系统内核的第一项重要功能 - 内存管理进行实验。
第二章 内存管理1 - 初始的地址空间和早期内存分配
内存管理是操作系统内核中最基础的功能,它几乎是其它所有功能得以运行的前提与支撑。因此,在内核启动的早期过程中,我们首先要建立内存管理方面的机制和功能,这通常包括两个部分:建立初始的地址空间和建立最初的动态内存分配机制。
第一节 基本概念 - 地址空间
地址空间是内核与应用的生存活动空间。内核或应用在运行中需要访问资源,主要包括三类资源:内存、I/O 端口以及中断编号(irq num)。具体到 RiscV 平台,前两类资源是统一进行编址的,它们在地址空间中由唯一的地址范围来标识;至于第三类 - 中断编号,本书不把它归入地址空间的范畴,我们将在第六章再来讨论。
对于 X86 体系结构,内存与 I/O 端口分别编址,需要通过不同的指令来访问这两类资源。
我们目前开发的内核是 Unikernel 形态,地址空间方面有其明显的特点:
- 只有单一的处于内核态的地址空间,内核与内嵌应用共用这一地址空间,不存在用户态进程空间(Unikernel其实连进程概念都没有)。
- 当内核刚启动时,这个地址空间是物理地址空间,空间布局由硬件平台所决定。
- 基于分页机制,我们可以在物理地址空间的基础上,新增虚拟地址空间,以获得更好的地址管理的灵活性。

CPU 有一个附属部件 MMU(Memory Management Unit),它的作用就是控制分页机制。MMU 默认是未启用分页的,所以内核启动时,直接看到的就是物理地址空间,并通过物理地址来访问资源,我们目前就正处在这个状态;然后内核创建页表,自定义虚拟地址空间的布局,然后通过设置 MMU 启用分页,分页启用后,虚拟地址空间开始发挥作用,它向内核遮蔽了真实的物理地址空间,内核看到的是经过精心映射后的虚拟地址空间,通过虚拟地址访问资源。虚拟地址空间中的各个地址范围,一部分会被实际映射到物理空间的某些地址区间上,而大部分会暂时或者永远处于未映射的状态,直接访问时将导致 Page Fault 异常。
物理地址空间是硬件平台生产构造时就已经确定的,而虚拟地址空间则是内核可以根据实际需要灵活定义和实时改变的,这是将来内核很多重要机制的基础。按照近年来流行的说法,分页机制赋予了内核“软件定义”地址空间的能力。
以下就针对我们的实验平台 qemu-riscv64-virt,进行分析和实验。
物理地址空间由硬件平台在生产时决定,通常以 FDT(flattened device tree)的形式提供。对于 qemu-riscv64-virt 平台,我们可以通过如下方式导出它的 fdt 文件。
当运行 make run 时,在屏幕输出中可以看到 qemu 的执行命令行:
Running on qemu...
qemu-system-riscv64 -m 128M -smp 1 -machine virt -bios default
-kernel target/riscv64gc-unknown-none-elf/release/axorigin.bin -nographic
-D qemu.log -d in_asm
注意上图中显示的 qemu-system-riscv64 执行时的命令行,修改这行命令,在参数 "-machine virt" 后面追加 ",dumpdtb=virt.dtb"。如此,命令的执行效果就发生了改变,不再是启动模拟器,而是导出名为 virt.dtb 的 fdt 文件,然后就退出了。得到的 virt.dtb 还只是二进制格式,进一步用 dtc 工具把它转换成可读的文本形式。执行的命令如下:
# 在参数"-machine virt"之后, 增加 ",dumpdtb=virt.dtb",用于导出fdt文件的二进制格式dtb
qemu-system-riscv64 -m 128M -smp 1 -machine virt,dumpdtb=virt.dtb \
-bios default -kernel target/riscv64gc-unknown-none-elf/release/axorigin.bin -nographic
# 把二进制形式virt.dtb,转化为可读的文本形式
dtc ./virt.dtb -o ./virt.dts
注意:执行上面的命令行导出 fdt 时,一定要保留所有参数。fdt 中很多配置项的值由 qemu 根据参数来决定。例如,对于物理内存的大小,qemu 参数指定
-m 128M来模拟 128M 的物理内存,相应的 fdt 中描述的 memory 就是 128M。
现在查看 virt.dts 的内容,仅节选与下步实验密切相关的部分:
/dts-v1/;
/ {
#address-cells = <0x02>;
#size-cells = <0x02>;
compatible = "riscv-virtio";
model = "riscv-virtio,qemu";
... ...
memory@80000000 {
device_type = "memory";
reg = <0x00 0x80000000 0x00 0x8000000>;
};
... ...
soc {
#address-cells = <0x02>;
#size-cells = <0x02>;
compatible = "simple-bus";
ranges;
... ...
serial@10000000 {
interrupts = <0x0a>;
interrupt-parent = <0x03>;
clock-frequency = "\08@";
reg = <0x00 0x10000000 0x00 0x100>;
compatible = "ns16550a";
};
... ...
virtio_mmio@10001000 {
interrupts = <0x01>;
interrupt-parent = <0x03>;
reg = <0x00 0x10001000 0x00 0x1000>;
compatible = "virtio,mmio";
};
... ...
};
};
现在先跳过 fdt 其它细节,注意 memory、serial和virtio_mmio 三个设备的 reg 字段,该字段描述了对应设备在地址空间中占据的地址区间范围,区间由起始地址和长度组成,是包含四个 32 位数的序列。对序列的解析需要依赖 #address-cells 和 #size-cells,它们如同编程中的变量作用域一样,内层定义可以覆盖外层。上面的示例中,它们分别在根和 soc 两级出现,且数值都是 2,这说明区间起始地址由两个值组成,长度也由两个值组成,它们都是 64 位数。fdt 采用大端序表示数据,所以物理内存 memory 的地址范围从 0x8000_0000 开始,大小是 0x800_0000 即 128M,这与当初在命令行中指定的参数是一致的;串口 serial 从 0x1000_0000 开始,长度 256 字节;第一个 virtio_mmio slot 的地址区间从 0x10001000 开始,长度是 4096 字节即 1 页,后面按顺序排列了另外 7 个 virtio_mmio slot。
现在可以画出我们实验平台大致的物理地址空间布局了:

在第零章,我们提到需要把 SBI 放到物理内存开始的位置 0x8000_0000 地址处,这里就知道了该地址可以从 fdt 中得知。此外,通过 fdt,我们还知道了 qemu 实验平台上,各个设备所占用的 mmio 范围集中安排在物理空间的低地址范围内。其中 virtio mmio slots 是后面实验中操作 virtio 设备的基础信息,我们将在第九章再分析它们。本章暂时只关注内存管理,即先完成内存部分 - 0x8000_0000 之后的虚拟地址空间映射。
从第一章我们知道,内核最早启动时,a1 寄存器保存的就是 fdt 二进制数据块 dtb 的开始指针。这个数据块与我们在本节中导出分析的 fdt 内容完全相同。fdt 是内核获取硬件平台配置信息的主要途径。目前为止,我们只是人工查看导出的 fdt 信息,为内核开发提供基础信息。到下一章的最后一节,我们将为内核实现自动解析 fdt 的功能,让内核在运行中自动获取这些关键信息。
下面就来考虑建立虚拟地址空间的问题。
本章我们建立的虚拟地址空间只需要与物理空间形成简单的线性映射,并且只处理包含 SBI 和 Kernel 存储区的 1G 范围。如下图,虚拟地址范围 0xFFFF_FFC0_8000_0000 ~ 0xFFFF_FFC0_C000_0000 线性映射到物理地址范围 0x8000_0000 ~ 0xC000_0000。

线性偏移的好处是,只需要通过加减偏移运算,就能完成虚拟地址与物理地址之间的转换。这个线性偏移常量称为 PHYS_VIRT_OFFSET,相应的运算公式表示为:
VA = PA + PHYS_VIRT_OFFSET;
PA = VA - PHYS_VIRT_OFFSET;
当前实验中 PHYS_VIRT_OFFSET=0xFFFF_FFC0_0000_0000,与我们选择的分页机制方案 Sv39 有关。我们开发的内核是 64 位系统,最大可用的地址空间范围是 64 位;但是按照 RiscV 规范,Sv39 有效的虚拟地址范围被约束为最大 39 位,从 40 位往上那些未使用的位必须与第 39 位一致。也就是说,如果第 39 位是 1,从第 40 位向上全部填充 1,有效范围 0xFFFF_FFC0_0000_0000 ~ 0xFFFF_FFFF_FFFF_FFFF;如果第 39 位是 0,高位全部填充 0,那么有效地址范围就是从 0 到 0x3F_FFFF_FFFF。这两个范围正处于64位空间最高端和最低端这两头的位置。按照惯例,我们选择了高端的这个范围,把它作为内核本身的虚拟地址空间;低端的那个范围暂时预留,将来支持宏内核模式时,我们把它作为应用进程的虚拟地址空间。
下面开始基于 Sv39 方案,建立我们内核的分页机制。
第二节 分页机制 - 页表和页表项
本节先来建立分页机制的基本数据结构 - 页表和页表项,为后面正式启用分页做准备。
从根页表开始,每一级页表都占用一个内存页,关于内存页大小,我们采用最典型的 4096 字节。Sv39 是针对 64 位系统的分页方案,即页表项长度是 8 字节,所以每个页表包含 512 个页表项。页表作为多级嵌套结构,由页表 page_table 和页表项 page_table_entry 两种基本元素交替构成,它们符合如下的模式:

每个页表 page_table 对应一个内存页,每个页划分为 512 个页表项 page_table_entry;页表项 page_table_entry 由物理页帧号 pfn 和标志位组 flags 这两部分构成。根据标志位不同,页表项有三种情况:
- 空页表项:尚未与物理页建立映射;
- 指向下级页表:pfn 保存的是下级页表的物理页帧号,当进行地址映射时,需要递归到下一级页表继续处理;
- 指向最终页:这种是叶子页表项(leaf entry),它的 pfn 直接就保存着一个物理页或者大页的页帧号。
下面来看一下 flags 各个位的具体功能定义,这里部分参照了 Linux 对各个位的命名:
/*
* RiscV64 PTE format:
* | XLEN-1 10 | 9 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0
* PFN reserved for SW D A G U X W R V
*/
const _PAGE_V : usize = 1 << 0; /* Valid */
const _PAGE_R : usize = 1 << 1; /* Readable */
const _PAGE_W : usize = 1 << 2; /* Writable */
const _PAGE_E : usize = 1 << 3; /* Executable */
const _PAGE_U : usize = 1 << 4; /* User */
const _PAGE_G : usize = 1 << 5; /* Global */
const _PAGE_A : usize = 1 << 6; /* Accessed (set by hardware) */
const _PAGE_D : usize = 1 << 7; /* Dirty (set by hardware)*/
const PAGE_TABLE: usize = _PAGE_V;
pub const PAGE_KERNEL_RO: usize = _PAGE_V | _PAGE_R | _PAGE_G | _PAGE_A | _PAGE_D;
pub const PAGE_KERNEL_RW: usize = PAGE_KERNEL_RO | _PAGE_W;
pub const PAGE_KERNEL_RX: usize = PAGE_KERNEL_RO | _PAGE_E;
pub const PAGE_KERNEL_RWX: usize = PAGE_KERNEL_RW | _PAGE_E;flags 从第 10 位往上是物理页帧号 pfn,而第 10 位是页表项的属性标志位。
第 0 位 V:页表项是否有效,当访问无效页面时,MMU 触发 Page Fault 之类的异常,这通常作为 Linux 等内核缺页加载的基本机制;
第 1~3 位 RWE:对映射后的页面是否分别具备读、写、执行权限,当越权访问时,MMU 触发 Access Fault 之类的异常,在 Linux 等内核实现中,可以基于该类异常实现 COW 写时拷贝;
第 4 位 U:表示这是用户页。由于实验内核是 Unikernel 形态,不存在用户态,所以这个位直接清零。
第 5 位 G:表示是全局页。这个位与 tlb 刷新有关。我们的 Unikernel 内核中,所有用到的页面都设置为全局页。
第 6~7 位 AD:分别表示 Accessed 访问过和 Dirty 被改写过。对于 Linux 等内核,通常是先把它们清零,如果运行过程中访问或改写了对应映射的页面,MMU 硬件会自动把它们置一,内核只要检查这两个位,就能知道是否发生过访问或改写的情况,这通常对页面置换策略有帮助。但是对我们的内核,没有涉及页面置换的问题,所以初始化时,只是简单的把它们都设置成一。
基于上述位,对外提供两个公开的复合标识。PAGE_KERNEL_RW 作为默认的地址映射标识,表示映射的页面存在并可以读写;PAGE_KERNEL_RWX 在此基础上增加执行权限。
实现一个新组件 page_table,首先包含上述标识定义,然后定义页表和页表项的数据结构和页表的初始化函数:
// page_table/src/lib.rs
#![no_std]
use axconfig::phys_pfn;
#[derive(Debug)]
pub enum PagingError {}
pub type PagingResult<T = ()> = Result<T, PagingError>;
const PAGE_PFN_SHIFT: usize = 10;
const ENTRIES_COUNT: usize = 1 << (PAGE_SHIFT - 3);
#[derive(Clone, Copy)]
#[repr(transparent)]
pub struct PTEntry(u64);
impl PTEntry {
pub fn set(&mut self, pa: usize, flags: usize) {
self.0 = Self::make(phys_pfn(pa), flags);
}
fn make(pfn: usize, prot: usize) -> u64 {
((pfn << PAGE_PFN_SHIFT) | prot) as u64
}
}
pub struct PageTable<'a> {
level: usize,
table: &'a mut [PTEntry],
}
impl PageTable<'_> {
pub fn init(root_pa: usize, level: usize) -> Self {
let table = unsafe {
core::slice::from_raw_parts_mut(root_pa as *mut PTEntry, ENTRIES_COUNT)
};
Self { level, table }
}
}第 14 行:页表项 PTEntry 是 64 位长度的数据项,后面会实现一些具体方法针对 pfn 和 flags 两个位域进行操作。
第 26~29 行:页表 PageTable 包括两个成员,level 是该页表所在的级别,根页表是 0,以此类推;table 数组对应页表包含的页表项序列。然后来看 init 初始化方法,以页表对应页面的物理地址为开始指针,构造页表项数组类型。注意:此时还没有启用分页,所以直接用物理地址。
页表操作的重点是映射方法 map,它负责建立从虚拟地址到物理地址的映射,先来看基于 SV39 分页方案,MMU 映射的原理:

SV39 包含三级页表,寄存器 satp 保持着根页表(0 级)页表的基地址,当访问虚拟地址 VA 时,它的低 39 位有效,MMU 的工作过程:
- 截取虚拟地址 VA 的第 30 至 38 位总共 9 位,作为索引查询根页表,找到对应页表项,分析页表项的flags;
- 如果页表项包含的是下级页表,则重复 1 和 2 的过程,最后定位到目标物理页帧,VA 的低 12 位作为页内偏移,与物理页帧合成最终的物理地址,完成映射;
- 如果页表项就是 Leaf 节点 - 即大页映射,则直接把 VA 剩余部分作为页内偏移,合并成最终的物理地址,提前完成映射。SV39 可能包含的大页有两级,1G 粒度和 2M 粒度。
我们在页表上执行 map 操作的目的,就是设置页表去匹配上面 MMU 的工作机制。
第一节最后提到,本章我们只需要建立初始的地址空间,即只映射包含 SBI 和内核的 1G 区间范围。根页表(evel0 table)是通过 linker.lds 在内核布局中预留的一页,不用额外分配,剩下的工作就是建立这 1G 空间的直接映射和设置 satp 寄存器来启用页表。下面先解决映射的问题,下一节实现页表启用。
我们为地址空间映射设计一个名为 map 的方法,原型如下:
fn map(&mut self, mut va: usize, mut pa: usize, mut total_size: usize, best_size: usize, flags: usize);涉及五个参数:
- 地址范围在虚拟空间中的开始位置,即虚拟地址 va;
- 地址范围在物理空间中的开始位置,即物理地址 pa;
- 地址范围的总长度 total_size;
- 期望按照哪一级粒度进行映射,可以是第一级 1G,第二级 2M 或第三级 4K,用 best_size 表示。第二章第二节中,就是基于第一级建立的 1G 大页映射。这个是期望,不是强制的。前三个参数必须按照 best_size 对齐;
- 映射的标志位集合 flags,决定映射的有效性、权限等等。

当前阶段的映射函数 map 非常简单,就是建立 1G 空间从虚拟到物理的映射,并且映射涉及的虚拟地址 va 和物理地址 pa 都是按照 1G 对齐的,所以 best_size 直接就是 1G,这样省略了很多额外的处理过程。等到了第四章重建地址空间映射时,情况会复杂的多,到时候我们再讨论不对齐的情况。
当前 map 方法的具体实现:
// page_table/src/lib.rs
impl PageTable<'_> {
const fn entry_shift(&self) -> usize {
ASPACE_BITS - (self.level + 1) * (PAGE_SHIFT - 3)
}
const fn entry_size(&self) -> usize {
1 << self.entry_shift()
}
pub const fn entry_index(&self, va: usize) -> usize {
(va >> self.entry_shift()) & (ENTRIES_COUNT - 1)
}
pub fn map(&mut self, mut va: usize, mut pa: usize,
mut total_size: usize, best_size: usize, flags: usize
) -> PagingResult {
let entry_size = self.entry_size();
while total_size >= entry_size {
let index = self.entry_index(va);
if entry_size == best_size {
self.table[index].set(pa, flags);
} else {
let mut pt = self.next_table_mut(index)?;
pt.map(va, pa, entry_size, best_size, flags)?;
}
total_size -= entry_size;
va += entry_size;
pa += entry_size;
}
Ok(())
}
fn next_table_mut(&mut self, _index: usize) -> PagingResult<PageTable> {
unimplemented!();
}
}第 3~5 行:方法 entry_shift 用来计算当前页表的页表项粒度,以 2^shift^ 表示。对于 SV39,ASPACE_BITS 是 39 位,这样 0 级根页表的页表项覆盖范围就是 1G,1 级页表的页表项对应 2M。
第 6~8 行:基于 entry_shift,计算页表项 entry 以数值方式表示的覆盖范围。
第 9~11 行:基于 entry_shift,把虚拟地址 VA 转化为当前页表中的对应索引值。
第 13~35 行:方法 map 的基本实现。参数 total_size 代表要映射的总范围,参数 best_size 则指明我们希望映射粒度到哪一级,可选值是 1G、2M 和 4K,如果选前两个值会建立大页映射。具体实现时,分别处理了直接大页映射和建立下级页表的情况。对于建立下级页表 next_table_mut,需要动态内存分配功能的支持,这里只预留了函数框架,等到第四章再补全,本章实验不会执行到这里。
现在页表的基本机制已经建立了,下面通过一个组件级的测试用例,验证页表功能,本章我们只需要验证第一级映射(即 level 0)。
// page_table/tests/test_early.rs
use axconfig::SIZE_1G;
use page_table::{PageTable, PAGE_KERNEL_RWX};
#[test]
fn test_early() {
let boot_pt: [u64; 512] = [0; 512];
let mut pt: PageTable = PageTable::init(boot_pt.as_ptr() as usize, 0);
let _ = pt.map(0x8000_0000, 0x8000_0000, SIZE_1G, SIZE_1G, PAGE_KERNEL_RWX);
let _ = pt.map(0xffff_ffc0_8000_0000, 0x8000_0000, SIZE_1G, SIZE_1G, PAGE_KERNEL_RWX);
assert_eq!(boot_pt[2], 0x200000ef, "pgd[2] = {:#x}", boot_pt[2]);
assert_eq!(boot_pt[0x102], 0x200000ef, "pgd[0x102] = {:#x}", boot_pt[0x102]);
}在根目录下 Cargo.toml 中,members 中追加 "page_table",执行 make test 测试:
Running tests/test_early.rs (target/debug/deps/test_early-45021e16a6b88d19)
running 1 test test test_early ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
第三节 启用分页 - 进入虚拟地址空间
上一节中我们已经实现了组件 page_table,本节就基于它来启用分页,让内核从物理地址空间进入到虚拟地址空间。

两步完成地址空间的切换:
- 第一步:恒等映射保证虚拟空间与物理空间有一个相等范围的地址空间映射(0x80000000~0xC0000000)。切换前后地址范围不变,但地址空间其实已经从物理空间切换到虚拟空间;
- 第二步:给指令指针寄存器 pc,栈寄存器 sp 等加偏移,在图中该偏移是 0xffff_ffc0_0000_0000,即 PHYS_VIRT_OFFSET。通过在虚拟空间内地址平移,我们就完成了最终的地址映射。
以下扩展组件 axhal,在 RiscV64 架构下实现一个 paging 的模块,用于处理与分页管理相关的功能。
- 新增 paging 模块,在其中初始化启动阶段的页表:
// axhal/src/riscv64/paging.rs
use riscv::register::satp;
use axconfig::SIZE_1G;
use page_table::{PageTable, PAGE_KERNEL_RWX, phys_pfn};
extern "C" {
fn boot_page_table();
}
pub unsafe fn init_boot_page_table() {
let mut pt: PageTable = PageTable::init(boot_page_table as usize, 0);
let _ = pt.map(0x8000_0000, 0x8000_0000, SIZE_1G, SIZE_1G, PAGE_KERNEL_RWX);
let _ = pt.map(0xffff_ffc0_8000_0000, 0x8000_0000, SIZE_1G, SIZE_1G, PAGE_KERNEL_RWX);
}第 10~14 行:函数 init_boot_page_table 调用上一节 page_table 组件的功能来初始化页表,其中第 12 行建立恒等映射,第 13 行则是建立了最终的地址映射关系。这两行为上面所述的两步切换,进行了页表方面的准备。
- 继续在 paging 模块中,增加启用分页的功能函数 init_mmu:
// axhal/src/riscv64/paging.rs
pub unsafe fn init_mmu() {
let page_table_root = boot_page_table as usize;
satp::set(satp::Mode::Sv39, 0, phys_pfn(page_table_root));
riscv::asm::sfence_vma_all();
}第 4 行:针对 satp 寄存器,进行了两项配置,指定 Sv39 分页模式和指定根页表的物理页帧号;
第 5 行:刷新 TLB,确保此后 MMU 使用最新的页表。
- 注意要把 paging 模块加到 riscv64 模块下。
// axhal/src/riscv64.rs
mod paging;- 调整内核启动过程,插入初始化页表和启用分页的过程,修改后 _start() 的实现如下:
// axhal/src/riscv64/boot.rs
use crate::riscv64::paging;
#[no_mangle]
#[link_section = ".text.boot"]
unsafe extern "C" fn _start() -> ! {
// a0 = hartid
// a1 = dtb
core::arch::asm!("
mv s0, a0 // save hartid
mv s1, a1 // save DTB pointer
la a3, _sbss
la a4, _ebss
ble a4, a3, 2f
1:
sd zero, (a3)
add a3, a3, 8
blt a3, a4, 1b
2:
la sp, boot_stack_top // setup boot stack
call {init_boot_page_table} // setup boot page table
call {init_mmu} // enabel MMU
li s2, {phys_virt_offset} // fix up virtual high address
add sp, sp, s2 // readjust stack address
mv a0, s0 // restore hartid
mv a1, s1 // restore DTB pointer
la a2, {entry}
add a2, a2, s2 // readjust rust_entry address
jalr a2 // call rust_entry(hartid, dtb)
j .",
init_boot_page_table = sym paging::init_boot_page_table,
init_mmu = sym paging::init_mmu,
phys_virt_offset = const axconfig::PHYS_VIRT_OFFSET,
entry = sym super::rust_entry,
options(noreturn),
)
}第 21 行:调用 init_boot_page_table 初始化页表;
第 22 行:通过 init_mmu 启用 MMU 的分页机制;
第 23 行:在 s2 寄存器存放 PHYS_VIRT_OFFSET,后面用于调整栈指针与指令寄存器偏移;
第 24行:调整栈指针寄存器 sp,指向最终的虚拟地址位置;
第 27~29 行:第 27 行以相对寻址的方式去取得 rust_entry 地址,实际上该地址仍是之前的物理地址,在第 28 行加偏移调整后,才是最终的虚拟地址,第 29 行跳转后完成指令寄存器 PC 中运行地址的最终切换。
在上述工作之外,还有两项新增的工作:
第 10~11 行:通过 s0 和 s1 分别对 a0 和 a1 进行保存:a0 和 a1 保持着当前 CPU 的 ID 和 DTB 指针,保存是要防止后面的函数调用破坏它们。
第 25~26 行:从 s0 和 s1 寄存器中恢复 a0 和 a1,紧跟着再调用 rust_entry 时,它们会作为前两个参数传入 CPU_ID 和 DTB 指针。
- 修改 linker.lds,把 BASE_ADDRESS 从 0x80200000 改成 0xffffffc080200000。在分页机制启用的条件下,我们要求内核 Image 中的各种符号地址都以虚拟地址为准,确保将来符号地址寻址的正确性。
执行 make clean & make run,可以看到内核在完成地址空间切换后,启动成功了。但是单从屏幕输出,我们看不出区别,下面利用 qemu.log 确认我们的工作成果。
我们知道当前版本的内核调用 rust_entry 时,已经进入到虚拟地址空间。所以先查找 rust_entry 的符号地址:
riscv64-unknown-elf-objdump -t ./target/riscv64gc-unknown-none-elf/release/axorigin | grep rust_entry
输出结果:
ffffffc0802000a6 l F .text 0000000000000070 _ZN5axhal7riscv6410rust_entry17hde9b663f0cccf0f7E
发现它对应的地址是 0xffffffc0802000a6(同学们的实验环境中该值可能不同),然后进一步在 qemu.log 查找该地址:
----------------
IN:
Priv: 1; Virt: 0
0x000000008020008a: 12000073 sfence.vma zero,zero
0x000000008020008e: 8082 ret
----------------
IN:
Priv: 1; Virt: 0
0x000000008020003a: 597d addi s2,zero,-1
0x000000008020003c: 191a slli s2,s2,38
0x000000008020003e: 914a add sp,sp,s2
0x0000000080200040: 8522 mv a0,s0
0x0000000080200042: 85a6 mv a1,s1
0x0000000080200044: 00000617 auipc a2,0 # 0x80200044
0x0000000080200048: 06260613 addi a2,a2,98
0x000000008020004c: 964a add a2,a2,s2
0x000000008020004e: 9602 jalr ra,a2,0
----------------
IN:
Priv: 1; Virt: 0
0xffffffc0802000a6: 711d addi sp,sp,-96
0xffffffc0802000a8: ec86 sd ra,88(sp)
注意第 23 行,0xffffffc0802000a6 是 rust_entry 地址,基于前面的工作,当进入 rust_entry 时,此时的运行地址相对之前发生了明显变化,证明内核已经从物理地址空间切换到了虚拟地址空间。
第四节 早期内存分配器的设计
在 Rust 开发中,String、Vector 之类的各种复合类型为我们带来了很大便利。但是我们的内核目前还不支持,因为没有实现动态内存分配器。我们可以来尝试一下,把 axorigin 的 main 函数改成这样:
// axorigin/src/main.rs
#![no_std]
#![no_main]
extern crate alloc;
use alloc::string::String;
use axhal::ax_println;
#[no_mangle]
pub fn main(_hartid: usize, _dtb: usize) {
let s = String::from("from String");
ax_println!("\nHello, ArceOS![{}]", s);
}通过 make build 编译一下,报错:
error: no global memory allocator found but one is required; link to std or add `#[global_allocator]` to a static item that implements the GlobalAlloc trait
果然不支持,String 需要动态内存即堆管理的支持,普通 Rust 应用经由 STD 标准库去申请底层操作系统内核对内存分配的支持,但是我们本身就是在实现内核,所以只能自己实现,即 - 我们按照 Rust 框架要求,实现内核级的动态内存分配器。
内核级内存分配器需要满足两个方面的要求:
- 分配器必须实现 GlobalAlloc trait,如 String、Vector 等集合数据类型都需要基于这个 trait 定义接口对分配器发出要求,请求以字节为最小分配单位。
- 内核的很多功能都要求申请以页为基本单位,并且开始地址按页对齐的分配块。这种按页分配在内核开发中是十分常用和必要的,有必要作为独立的服务接口对外提供。
总结一下,功能上我们需要两种相互独立的内存分配器,一种基于字节分配,另一种基于页分配。
当前阶段,我们先采用最简单的设计方案,即让一个分配器同时支持两种分配功能。

分配机制:字节与页分配共用同一块内存空间,从前向后字节分配,从后向前页分配。它们分别使用一个指针维护当前到达的位置。
释放机制,同样采取最简单的策略:
- 针对字节分配,用 count 变量记录分配次数,仅在 count 回复到零时,才把当前位置指针重置成起始位置。也就是说,只有在所有申请的内存块全部释放时,才真正的释放空间。这样的内存使用效率当然不高,但在引导阶段这不是问题。
- 对于页分配,没有为它设计释放机制。一方面是为了简单,另一方面在早期内存分配器生效的这段时间,内核需要申请的页都是它这一生都需要的,所以并不需要释放。
建立新组件 axalloc 在内核中负责动态内存分配的功能。未来几章,我们将在该组件中定义一系列内存分配器,用于不同阶段和不同类型,本章首先定义早期内存分配器 EarlyAllocator:
// axalloc/src/lib.rs
#![no_std]
extern crate alloc;
mod early;
#[derive(Debug)]
pub enum AllocError {
InvalidParam,
MemoryOverlap,
NoMemory,
NotAllocated,
}
pub type AllocResult<T = ()> = Result<T, AllocError>;
// axalloc/src/early.rs
#![allow(dead_code)]
use core::alloc::Layout;
use core::ptr::NonNull;
use axconfig::{align_up, align_down, PAGE_SIZE};
use crate::{AllocResult, AllocError};
#[derive(Default)]
pub struct EarlyAllocator {
start: usize,
end: usize,
count: usize,
byte_pos: usize,
page_pos: usize,
}
impl EarlyAllocator {
pub fn init(&mut self, start: usize, size: usize) {
self.start = start;
self.end = start + size;
self.byte_pos = start;
self.page_pos = self.end;
}
pub const fn uninit_new() -> Self {
Self {
start: 0, end: 0, count: 0,
byte_pos: 0, page_pos: 0,
}
}
}
// axalloc/Cargo.toml
[dependencies]
axconfig = { path = "../axconfig" }第 33~38 行:指定地址范围初始化分配器,字节分配指针 byte_pos 和页分配指针 page_pos 的初始位置分别在两端。
第 17 行:目前临时加上 #![allow(dead_code)] 以屏蔽警告,等到正式引用 EarlyAllocator 时再取消这行。
然后是字节分配功能的实现:
// axalloc/src/early.rs
impl EarlyAllocator {
pub fn alloc_bytes(&mut self, layout: Layout) -> AllocResult<NonNull<u8>> {
let start = align_up(self.byte_pos, layout.align());
let next = start + layout.size();
if next > self.page_pos {
alloc::alloc::handle_alloc_error(layout)
} else {
self.byte_pos = next;
self.count += 1;
NonNull::new(start as *mut u8).ok_or(AllocError::NoMemory)
}
}
pub fn dealloc_bytes(&mut self, _ptr: NonNull<u8>, _layout: Layout) {
self.count -= 1;
if self.count == 0 {
self.byte_pos = self.start;
}
}
fn total_bytes(&self) -> usize {
self.end - self.start
}
fn used_bytes(&self) -> usize {
self.byte_pos - self.start
}
fn available_bytes(&self) -> usize {
self.page_pos - self.byte_pos
}
}第 3~13 行:字节分配方法,从前往后分配。首先对分配范围的开始位置对齐,然后计算结束位置并检查越界。注意:是否越界参照的是页分配指针 page_pos 指向的当前位置,而不是整个区域的结束位置。通过检查后,就把结束位置作为下次分配的开始搜索位置;另外,把 count 计数加一,用于记录已分配的块数。
第 15~20 行:字节释放方法,每释放一块就把计数 count 减一。当 count 减到 0 时,意味着之前分配的所有内存块都已经释放,字节分配指针回到初始位置。
第 22~30 行:监控字节分配率的三个方法,其中 available_bytes 是 page_pos 与 byte_pos 之间的区域长度。
执行 make test 先来测试一下字节分配的功能:
// axalloc/src/early.rs
#[cfg(test)]
mod tests;
// axalloc/src/early/tests.rs
use axconfig::PAGE_SIZE;
use core::alloc::Layout;
use super::EarlyAllocator;
#[test]
fn test_alloc_bytes() {
let space: [u8; PAGE_SIZE] = [0; PAGE_SIZE];
let base = space.as_ptr() as usize;
let mut early = EarlyAllocator::default();
early.init(base, PAGE_SIZE);
assert_eq!(early.total_bytes(), PAGE_SIZE);
assert_eq!(early.available_bytes(), PAGE_SIZE);
assert_eq!(early.used_bytes(), 0);
let layout = Layout::from_size_align(2, 2).unwrap();
let p0 = early.alloc_bytes(layout).unwrap();
assert_eq!(p0.as_ptr() as usize - base, 0);
assert_eq!(early.used_bytes(), 2);
let layout = Layout::from_size_align(4, 4).unwrap();
let p1 = early.alloc_bytes(layout).unwrap();
assert_eq!(p1.as_ptr() as usize - base, 4);
assert_eq!(early.used_bytes(), 8);
early.dealloc_bytes(p0, Layout::new::<usize>());
early.dealloc_bytes(p1, Layout::new::<usize>());
assert_eq!(early.total_bytes(), PAGE_SIZE);
assert_eq!(early.available_bytes(), PAGE_SIZE);
assert_eq!(early.used_bytes(), 0);
}从后向前是为页分配准备的区域,如前所述,在内核引导的早期申请的页面会一直使用,所以只需要实现 alloc_pages:
// axalloc/src/early.rs
impl EarlyAllocator {
pub fn alloc_pages(&mut self, layout: Layout) -> AllocResult<NonNull<u8>> {
assert_eq!(layout.size() % PAGE_SIZE, 0);
let next = align_down(self.page_pos - layout.size(), layout.align());
if next <= self.byte_pos {
alloc::alloc::handle_alloc_error(layout)
} else {
self.page_pos = next;
NonNull::new(next as *mut u8).ok_or(AllocError::NoMemory)
}
}
pub fn total_pages(&self) -> usize {
(self.end - self.start) / PAGE_SIZE
}
pub fn used_pages(&self) -> usize {
(self.end - self.page_pos) / PAGE_SIZE
}
pub fn available_pages(&self) -> usize {
(self.page_pos - self.byte_pos) / PAGE_SIZE
}
}第 4 行:页分配必须按页对齐。
第 5 行:从后向前查找可分配的页内存区,并且这个待分配内存区的开始地址必须按页对齐。
第 6~7 行:检查越界 - 新申请的页内存分配区域不能与现有的字节分配区域重叠。
第 9~10 行:在 page_pos 中记录当前分配到的位置,并成功返回内存块的地址。
第 14~22 行:跟踪页分配情况的三个方法,同样,注意 available_pages 对应的是 page_pos 和 byte_pos 之间的区域长度。
现在来验证页分配功能,执行测试 make test:
// axalloc/src/early/tests.rs
#[test]
fn test_alloc_pages() {
let num_pages = 16;
let total_size = PAGE_SIZE * num_pages;
let layout = Layout::from_size_align(total_size, PAGE_SIZE).unwrap();
let space = unsafe { alloc::alloc::alloc(layout) };
let start = space as usize;
let end = start + total_size;
let mut early = EarlyAllocator::default();
early.init(start, total_size);
assert_eq!(early.total_pages(), num_pages);
assert_eq!(early.available_pages(), num_pages);
assert_eq!(early.used_pages(), 0);
let layout = Layout::from_size_align(PAGE_SIZE, PAGE_SIZE).unwrap();
let p0 = early.alloc_pages(layout).unwrap();
assert_eq!(p0.as_ptr() as usize, end - PAGE_SIZE);
assert_eq!(early.used_pages(), 1);
let layout = Layout::from_size_align(PAGE_SIZE*2, PAGE_SIZE).unwrap();
let p1 = early.alloc_pages(layout).unwrap();
assert_eq!(p1.as_ptr() as usize, end - PAGE_SIZE*3);
assert_eq!(early.used_pages(), 3);
}本节我们为内核准备了一个早期引导过程中使用的动态内存分配器,它同时支持字节分配和页分配的功能。
但是该分配还没有启用,所以如果此时 make run 去运行本节开头的 axorigin 中的新代码,仍然会报同样的错误。下节我们来启用内存分配器,让内核初步支持动态内存分配。
第五节 启用动态内存分配
本节为内核启用动态内存分配功能,主要分两个步骤:
- 向 Rust 声明一个支持 GlobalAlloc Trait 的内存分配器 GlobalAllocator,这个 Trait 是向 Rust 提供动态内存分配服务的标准接口。
- 初始化内存分配器,为它指定可以使用的内存地址范围。

如上图,全局内存分配器 GlobalAllocator 实现 GlobalAlloc Trait,它包含两个功能:字节分配和页分配,分别用于响应对应请求。区分两种请求的策略是,请求分配的大小是页大小的倍数且按页对齐,就视作申请页;否则就是按字节申请分配。这两个内部功能可以由各种内存分配算法支持实现,当前是内核启动早期,我们基于上节提供的 early allocator支持两种功能。
全局内存分配器启用时必须指定一组可用的内存地址范围(至少一个)。在内核启动早期,通过 early_init 方法初始化并启用,这就是本节要实现的主要内容;然后在适当时刻,调用 final_init 方法切换到正式的内存分配器,这是第四章将要介绍的内容。
下面来实现全局内存分配器 GlobalAllocator,首先引入一些必须依赖的外部符号:
// axalloc/src/lib.rs
use core::alloc::Layout;
use core::ptr::NonNull;
use spinlock::SpinRaw;
use axconfig::PAGE_SIZE;
extern crate alloc;
use alloc::alloc::GlobalAlloc;
mod early;
use early::EarlyAllocator;实现全局的内存分配器:
// axalloc/src/lib.rs
#[cfg_attr(not(test), global_allocator)]
static GLOBAL_ALLOCATOR: GlobalAllocator = GlobalAllocator::new();
struct GlobalAllocator {
early_alloc: SpinRaw<EarlyAllocator>,
}
impl GlobalAllocator {
pub const fn new() -> Self {
Self {
early_alloc: SpinRaw::new(EarlyAllocator::uninit_new()),
}
}
pub fn early_init(&self, start: usize, size: usize) {
self.early_alloc.lock().init(start, size)
}
}分别为字节分配和页分配准备方法:
// axalloc/src/lib.rs
impl GlobalAllocator {
fn alloc_bytes(&self, layout: Layout) -> *mut u8 {
if let Ok(ptr) = self.early_alloc.lock().alloc_bytes(layout) {
ptr.as_ptr()
} else {
alloc::alloc::handle_alloc_error(layout)
}
}
fn dealloc_bytes(&self, ptr: *mut u8, layout: Layout) {
self.early_alloc.lock().dealloc_bytes(
NonNull::new(ptr).expect("dealloc null ptr"),
layout
)
}
fn alloc_pages(&self, layout: Layout) -> *mut u8 {
if let Ok(ptr) = self.early_alloc.lock().alloc_pages(layout) {
ptr.as_ptr()
} else {
alloc::alloc::handle_alloc_error(layout)
}
}
fn dealloc_pages(&self, _ptr: *mut u8, _layout: Layout) {
unimplemented!();
}
}现在如果进行编译,Rust 会提示需要 GlobalAlloc Trait,这个 Trait 是 GlobalAllocator 必须实现的标准接口。
实现 GlobalAlloc Trait 的两个方法 - 分配 alloc 和释放 dealloc,如下:
// axalloc/src/lib.rs
unsafe impl GlobalAlloc for GlobalAllocator {
unsafe fn alloc(&self, layout: Layout) -> *mut u8 {
if layout.size() % PAGE_SIZE == 0 && layout.align() == PAGE_SIZE {
self.alloc_pages(layout)
} else {
self.alloc_bytes(layout)
}
}
unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout) {
if layout.size() % PAGE_SIZE == 0 && layout.align() == PAGE_SIZE {
self.dealloc_pages(ptr, layout)
} else {
self.dealloc_bytes(ptr, layout)
}
}
}
pub fn early_init(start: usize, len: usize) {
GLOBAL_ALLOCATOR.early_init(start, len)
}现在准备启用:
上一节开头,我们让 axorigin 向屏幕输出 String 类型,结果报错 - “没有全局内存分配器”。如下在使用 String 类型变量之前,首先对 axalloc 组件进行初始化,启用内存分配功能。
// axorigin/src/main.rs
#![no_std]
#![no_main]
extern crate alloc;
use alloc::string::String;
use axhal::ax_println;
#[no_mangle]
pub fn main(_hartid: usize, _dtb: usize) {
extern "C" {
fn _skernel();
}
// We reserve 2M memory range [0x80000000, 0x80200000) for SBI,
// but it only occupies ~194K. Split this range in half,
// requisition the higher part(1M) for early heap.
axalloc::early_init(_skernel as usize - 0x100000, 0x100000);
let s = String::from("from String");
ax_println!("\nHello, ArceOS![{}]", s);
}
// axorigin/Cargo.toml
[dependencies]
axhal = { path = "../axhal" }
axalloc = { path = "../axalloc" }第14~17行:如注释所述,我们使用内核前面 1M 的地址范围来初始化内存分配器,在 RiscV64 架构下这部分内存是确定空闲的。虽然只有 1M,但对于早期启动阶段来说已经足够了,第四章我们将切换到正式的内存分期器,管理所有的 Heap 区域。
在内核启动早期,我们不想直接使用内核后面的内存区域来初始化内存分配器。此时,内核尚未对系统的整体内存分布状况进行调查,还不知道具体有几块内存区域以及它们的大小,如直接使用可能会引入一些不确定因素。所以目前先使用确定的空闲区域初始化一个临时的小型的早期内存分配器,以方便后续引导过程的实现。
现在可以测试了,make run 看看输出结果:
Hello, ArceOS![from String]
验证成功!
第六节 内核分层和主干组件
前面我们已经启用了内存分配器组件 axalloc,对它的初始化工作临时放在了应用组件 axorigin 中。显然这是不合适的,内存分配器作为内核的关键组成部分应当划分到系统层,并在系统层就被初始化。但在此之前,我们将重新分析和规划整个系统的框架和分层。
回顾第一章的第三节,我们把系统简单分成了两层,应用层包含应用组件 axorigin,系统层仅包含硬件抽象组件 axhal。
实际上对于系统层,又可以进一步划分为硬件体系无关与硬件体系相关的两个层次。硬件体系相关的工作已经由 axhal 承担,现在我们再增加一级硬件体系无关的层次,该层的核心组件 axruntime 专门用来对通用的、硬件体系无关的各类组件进行组织和初始化。
此外,在应用层与系统层之间,常规上还需要一层应用接口库,负责封装屏蔽系统内部复杂性,方便应用的开发。其中关键组件 axstd,顾名思义,功能上相当于 Rust 官方 STD 库的作用。
这样系统就形成了如下的四层结构,每一层都由一个核心组件负责串联:

自底向上四个层次的核心组件分别是 axhal、axruntime、axstd 和 axorigin,它们构成了框架主干,在系统中是必须存在和不可替代的;除主干之外的其它组件都称为功能组件,往往是可选和可配置的,某些功能可能存在多个候选组件。由主干组件负责对功能组件进行接入、初始化和管理。
另外一个需要注意的问题:启动过程中,各层次主干组件的调用关系是自底向上,基于 extern ABI 的形式;而运行过程则是自顶向下调用,预先通过 Cargo.toml 中的 dependencies 建立依赖链。至于为何采用这样的设计,请回顾第一章第三节关于循环依赖的问题。
下面我们就将引入 axstd 和 axruntime 这两个新组件,并分别针对启动和运行两个过程对系统框架进行相应的调整。
启动过程的调整(自底向上)
先来改造 axhal,它的 rust_entry 中需要以 extern ABI 方式调用 axruntime 的 rust_main 入口:
// axhal/src/riscv64.rs
mod lang_items;
mod boot;
pub mod console;
mod paging;
unsafe extern "C" fn rust_entry(hartid: usize, dtb: usize) {
extern "C" {
fn rust_main(hartid: usize, dtb: usize);
}
rust_main(hartid, dtb);
}建立组件 axruntime 并实现它的主入口函数 rust_main,该函数未来将会包含内核启动的各个主要过程:
// axruntime/src/lib.rs
#![no_std]
pub use axhal::ax_println as println;
#[no_mangle]
pub extern "C" fn rust_main(_hartid: usize, _dtb: usize) -> ! {
extern "C" {
fn _skernel();
fn main();
}
println!("\nArceOS is starting ...");
// We reserve 2M memory range [0x80000000, 0x80200000) for SBI,
// but it only occupies ~194K. Split this range in half,
// requisition the higher part(1M) for early heap.
axalloc::early_init(_skernel as usize - 0x100000, 0x100000);
unsafe { main(); }
loop {}
}第 4 行:引入 axhal 定义的标准输出宏 ax_println,并且把它 re-export 出去,后面 axstd 将继续把它暴露给应用。
第 17 行:把对 axalloc 的初始化从应用 axorigin 中转移到 rust_main 中。
第 18 行:调用 axorigin 的入口 main。
然后是对应调整 axorigin 的 main 函数:
// axorigin/src/main.rs
#![no_std]
#![no_main]
use axstd::{String, println};
#[no_mangle]
pub fn main(_hartid: usize, _dtb: usize) {
let s = String::from("from String");
println!("\nHello, ArceOS![{}]", s);
}第 5 行:应用只与接口库 axstd 交互,使用它提供的类型、方法及宏,所以我们将让 axstd 公开这些声明。
运行过程的调整(自顶向下)
建立从 axorigin -> axstd -> axruntime -> axhal 的依赖关系:
# axorigin/Cargo.toml
[dependencies]
axstd = { path = "../axstd" }
# axstd/Cargo.toml
[dependencies]
axruntime = { path = "../axruntime" }
axhal = { path = "../axhal" }
# axruntime/Cargo.toml
[dependencies]
axhal = { path = "../axhal" }
axalloc = { path = "../axalloc" }
第 12 行:axruntime 负责初始化 axalloc,建立对它的依赖。
应用接口库组件 axstd 的实现:
// axstd/src/lib.rs
#![no_std]
extern crate alloc;
pub use alloc::string::String;
pub use axruntime::println;第 5 行:直接 re-export Rust 的 alloc 库中定义的 String 类型。
第 6 行:把 axruntime 声明的 println 宏公开给应用层调用。
上述 5 和 6 行的目的都是尽可能简化应用开发,让开发者获得类似于在 Linux/Windows 上开发 Rust 应用的体验。
代码调整完毕,但还需要更新一下测试方面的设置。新增 axruntime 和 axstd 组件后,make test 在遇到这两个组件时,会报错。
我们对内核的测试主要针对各个功能组件,所以屏蔽 axruntime 和 axstd 组件,以减少测试过程中不必要的干扰:
# Makefile
test:
cargo test --workspace --exclude "axorigin" --exclude "axruntime" --exclude "axstd" -- --nocapture
看一下当前根目录下的 Cargo.toml 内容:
[workspace]
resolver = "2"
members = [
"axorigin", "axhal", "axconfig", "spinlock", "axsync", "page_table", "axalloc",
"axruntime", "axstd",
]
[profile.release]
lto = true
现在可以执行测试,看我们最近对内核的修改是否影响了之前的功能。
执行 make test:测试全部通过!
最后验证整个内核在调整整体框架后的功能,执行 make run,看结果:
ArceOS is starting ...
Hello, ArceOS![from String]
输出正常!
本章总结
本章我们首先引入了地址空间的概念,设计了内核在早期引导过程中的地址空间布局。然后按照布局要求,建立了最初的页表,并基于 RiscV64 硬件机制启用分页,进入到虚拟地址空间,为后面各种功能组件的初始化和运行建立了基础。为了让后面的内核开发过程可以使用 Rust 提供的高级类型,我们建立了早期的内存分配器,虽然它的最大分配能力只有 1M,但是已经足以支撑内核的早期启动工作。等我们能够通过解析 fdt 信息获取实际的物理内存大小之后,将会构建并切换到正式的内存分配器。最后,我们引入了 axruntime 和 axstd 这两个组件,形成了典型的四层系统架构,现在内核的主干框架已经齐备,后面我们将基于这个框架不断扩展功能组件,逐步接近设计目标。
第三章 基础组件 - 时间、日志和设备树
【正式启动前的准备】
通过前面几章的实验,我们的内核已经初具雏形,但是仍然欠缺一些基础设施,包括时间、日志以及设备树解析器等等。它们对下一步继续扩展内核的各个子系统,将会起到重要的支撑作用。
第一节 获得系统时间
系统时间是支持内核运行最重要的基础之一,也是应用需要获取的重要服务之一。获取系统时间必须基于硬件平台提供的时间寄存器,它们本质上就是由晶振驱动的计数器。对 RiscV64 来说,在 M-Mode 有一个专门的计数寄存器 mtime 作为计算时间的基础,它在 S-Mode 被映射为名为 time 的寄存器,所以内核虽然运行在 S-Mode,也可以读出该寄存器的值。按照规范文档的说法,time 是 mtime 的 shadow。
既然获取系统时间是体系结构相关的功能,我们把它放到 axhal 中实现。
// axhal/src/riscv64/time.rs
use core::time::Duration;
use riscv::register::time;
const TIMER_FREQUENCY: u64 = 10_000_000; // 10MHz
const NANOS_PER_SEC: u64 = 1_000_000_000;
const NANOS_PER_TICK: u64 = NANOS_PER_SEC / TIMER_FREQUENCY;
pub type TimeValue = Duration;
#[inline]
pub fn current_ticks() -> u64 {
time::read() as u64
}
#[inline]
pub const fn ticks_to_nanos(ticks: u64) -> u64 {
ticks * NANOS_PER_TICK
}
pub fn current_time_nanos() -> u64 {
ticks_to_nanos(current_ticks())
}
pub fn current_time() -> TimeValue {
TimeValue::from_nanos(current_time_nanos())
}
// axhal/src/riscv64.rs
pub mod time;第18行:核心函数 current_ticks(),返回 ticks 计数值;其他函数都以它为基础进行计算。
第22行:对外提供时间服务的主要函数。无论是内核模块还是应用接口库都是经由它获取系统时间。
本节我们先来扩展 axstd,参照 Rust 官方 STD 库的实现方式,提供 Instant 类型和相关方法,向应用提供时间功能:
// axstd/src/time.rs
use core::time::Duration;
use core::ops::Sub;
use core::fmt;
#[derive(Clone, Copy)]
pub struct Instant(axhal::time::TimeValue);
impl Instant {
pub fn now() -> Instant {
Instant(axhal::time::current_time())
}
pub fn elapsed(&self) -> Duration {
Instant::now() - *self
}
pub fn duration_since(&self, earlier: Instant) -> Duration {
self.0.checked_sub(earlier.0).unwrap_or_default()
}
}
impl Sub<Instant> for Instant {
type Output = Duration;
fn sub(self, other: Instant) -> Self::Output {
self.duration_since(other)
}
}
impl fmt::Display for Instant {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "{}.{:06}", self.0.as_secs(), self.0.subsec_micros())
}
}
// axstd/src/lib.rs
pub mod time;
pub use time::*;现在,我们可以在应用 axorigin 中,测试一下获取时间的功能:
// axorigin/src/main.rs
#![no_std]
#![no_main]
use axstd::{String, println, time};
#[no_mangle]
pub fn main(_hartid: usize, _dtb: usize) {
let now = time::Instant::now();
println!("\nNow: {}", now);
let s = String::from("from String");
println!("Hello, ArceOS![{}]", s);
let d = now.elapsed();
println!("Elapsed: {}.{:06}", d.as_secs(), d.subsec_micros());
}执行 make run 测试,显示结果:
ArceOS is starting ...
Now: 0.103643 Hello, ArceOS![from String] Elapsed: 0.003917
获取时间功能验证成功!
第二节 组件 crate_interface - 打破循环依赖
在基于 Rust 语言开发时,可以通过引用现有的 crate 来引入其功能,基本方式就是在 Cargo.toml 中建立对外部 crate 的依赖,然后就可以像引用内部模块一样调用它的代码。但是这种方式是有局限性的,如果两个 crate 之间存在相互依赖,或者多个 crate 存在环形依赖,都会阻碍编译。我们称这种问题为循环依赖。
我们的内核基于组件化思想并且采用 Rust 语言实现,在这种开发条件下,crate 是作为组件的实现形式。在后面的开发过程中,我们将经常会遇到循环依赖的问题,例如下节将要引入的 axlog 日志组件:
组件 axruntime 在初始化时,将会初始化 axhal 和 axlog 这两个组件。对于 axhal 和 axlog 这两个组件来说,一方面,axhal 组件需要日志功能,所以依赖 axlog 组件;与此同时,axlog 必须依赖 axhal 提供的标准输出或写文件功能以实现日志输出,所以 axlog 又反过来依赖 axhal。这就在二者之间形成了循环依赖。所以我们必须想办法替换其中一个方向的依赖,以打破循环依赖。
在 Rust 开发中,还存在一种 extern ABI 的机制,见 Rust 参考手册External blocks - The Rust Reference (rust-lang.org) 中关于 ABI 的那一节。形式上采用 extern "Rust" 来声明外部函数,随后就可以在当前 crate 中直接调用该函数。本质上这是一种在低级的 ABI 层面进行符号引用的方法,好处是不用在 Cargo.toml 中定义依赖,可以跳出循环依赖的限制;但是不利之处在于,它是 unsafe 方式,Rust 不做参数正确性检查,不保证其安全性。
为了提高上述方式的可读和易用性,降低编码出错的可能,我们创建一个组件 crate_interface,基于一组过程宏 proc_macro 来封装 extern ABI 的机制。以后在我们的内核开发中,将会经常用到这个组件。
下面仍然以 axhal 和 axlog 为例,说明 crate_interface 的用法。我们选择让 axhal 通过 Cargo.toml 的 [dependencies] 对 axlog 建立依赖,而 axlog 对 axhal 的反向引用基于 crate_interface 提供的机制,如下图:

-
通过 #[def_interface] 宏,在 axlog 中定义一个跨 crate 的接口 LogIf
接口 LogIf 包含调用方和实现方交互的两个具体方法,分别是写字符串 write_str() 和获取当前时间 get_time()。为方便,直接把 LogIf 定义在 axlog 中。
// axlog/src/lib.rs #![no_std] #[crate_interface::def_interface] pub trait LogIf { fn write_str(s: &str); fn get_time() -> core::time::Duration; } // axlog/Cargo.toml [dependencies] crate_interface = "0.1.1"第 4 行:过程宏 crate_interface::def_interface 在预编译的过程中,对 Trait LogIf 的声明进行处理。
预编译处理后,形成如下形式的代码。
extern "Rust" { fn __LogIf_write_str(s: &str); fn __LogIf_get_time() -> core::time::Duration; }可以看到,实际上就是声明了一组 extern "Rust" 的外部函数,每个函数对应 LogIf 的一个方法,函数名是接口名+对应方法名。这样将来在引入了 LogIf 接口的代码文件中,就可以调用这些外部函数了。当然我们不需要直接调用,继续看下面的封装。
-
在 axhal 中定义 LogIfImpl 实现 LogIf 接口,并通过 #[impl_interface] 宏进行标记,说明它是一个跨 crate 的接口实现:
// /axhal/src/riscv64.rs struct LogIfImpl; #[crate_interface::impl_interface] impl axlog::LogIf for LogIfImpl { fn write_str(s: &str) { console::write_bytes(s.as_bytes()); } fn get_time() -> core::time::Duration { time::current_time() } } // axhal/Cargo.toml [dependencies] axconfig = { path = "../axconfig" } page_table = { path = "../page_table" } axlog = { path = "../axlog" } crate_interface = "0.1.1"第 4 行:过程宏 crate_interface::impl_interface 在预编译阶段,处理第 5 到第 13 行的 LogIfImpl 实现。
效果是新增了如下形式的代码:
extern "Rust" { fn __LogIf_write_str(s: &str) { let IMPL: LogIfImpl = LogIfImpl; IMPL.write_str(s) } fn __LogIf_get_time() -> core::time::Duration { let IMPL: LogIfImpl = LogIfImpl; IMPL.get_time() } }实际就是生成了两个框架函数 __LogIf_write_str 和 __LogIf_get_time,符号名与 def_interface 生成的两个外部函数声明是对应一致的。它们同样是放在 extern "Rust" 代码块中,将作为跨 crate 的符号使用。当其它 crate 调用这两个框架函数时,它们在内部生成 LogIfImpl 的临时实例,并调用其对应的实现方法。
-
通过宏 call_interface!(LogIf::XXX) 调用 LogIf 的实现
在 axlog 中定义函数 init(),在其中通过
call_interface!这个宏去调用接口 LogIf,如下:pub fn init() { extern crate alloc; let now = crate_interface::call_interface!(LogIf::get_time()); let s = alloc::format!("Logging startup time: {}.{:06}", now.as_secs(), now.subsec_micros()); crate_interface::call_interface!(LogIf::write_str(s.as_str())); }第 4 行:call_interface! 宏调用 LogIf::get_time,预编译后该宏被替换为如下形式的代码:
unsafe { __LogIf_get_time() }第 7 行:call_interface! 宏调用 LogIf::write_str,预编译后该宏被替换为如下形式的代码:
unsafe { __LogIf_write_str(s) }也就是说第 4 和第 7 行会转化为对这两个跨 crate 外部函数的调用。回顾前面的第 1 项已经通过 def_interface 宏处理 LogIf,声明了这两个符号,这里直接调用即可。最后,Rust 链接器会对调用方和实现方的符号进行链接,由此在 ABI 层面完成调用关系的建立。
-
下面来验证 crate_interface 的功能。
在 axruntime 组件的初始化过程中,初始化 axlog。
//axruntime/src/lib.rs #[no_mangle] pub extern "C" fn rust_main(_hartid: usize, _dtb: usize) -> ! { extern "C" { fn _skernel(); fn main(); } println!("\nArceOS is starting ..."); // We reserve 2M memory range [0x80000000, 0x80200000) for SBI, // but it only occupies ~194K. Split this range in half, // requisition the higher part(1M) for early heap. axalloc::early_init(_skernel as usize - 0x100000, 0x100000); axlog::init(); unsafe { main(); } loop {} } // axruntime/Cargo.toml [dependencies] axhal = { path = "../axhal" } axalloc = { path = "../axalloc" } axlog = { path = "../axlog" }注意:第 16 行调用 axlog::init() 中需要动态申请内存,所以它必须放在第 14 行 axalloc::early_init 动态内存初始化之后。
执行
make run,查看结果:ArceOS is starting ... Logging startup time: 0.122987 Now: 0.126629 Hello, ArceOS![from String] Elapsed: 0.001787
上面打印了 logging 成功启动的信息!当然本节主要目标是介绍 crate_interface 组件,axlog 只是作为示例引入,下一节我们将会给出 axlog 组件的完整实现。
最后来总结一下,组件 crate_interface 实现了如下的效果:
基于预定义的接口 trait,在任意 crate 中对该接口的功能实现,可以被其它任意 crate 中的代码所调用。实现方和调用方之间在 ABI 层完成链接,不需要通过 Cargo.toml 建立依赖就可以实现跨 crate 的接口调用,可以跳出循环依赖的限制。
第三节 组件 axlog - 支持 log
现在我们来为内核正式实现日志组件 axlog。在 crates.io 中已经有一个非常通用的日志 crate - log,它主要用于普通应用的开发;本节我们将以它为基础进行封装和扩展,满足内核对日志设施的需要。
首先实现日志的初始化过程和级别设置:
// axlog/Cargo.toml
[dependencies]
log = "0.4"
crate_interface = "0.1.1"
// axlog/src/lib.rs
#![no_std]
use core::fmt::{self, Write};
use core::str::FromStr;
use crate_interface::call_interface;
use log::{Level, LevelFilter, Log, Metadata, Record};
pub use log::{debug, error, info, trace, warn};
#[crate_interface::def_interface]
pub trait LogIf {
fn write_str(s: &str);
fn get_time() -> core::time::Duration;
}
struct Logger;
pub fn init() {
log::set_logger(&Logger).unwrap();
log::set_max_level(LevelFilter::Warn);
}
pub fn set_max_level(level: &str) {
let lf = LevelFilter::from_str(level).ok().unwrap_or(LevelFilter::Off);
log::set_max_level(lf);
}第 4 行:Cargo.toml 引入 log 和 crate_interface 两个 crates。
第 21 行:全局的日志实例 Logger,它代表了日志对象,将来对日志的各种操作主要都是针对它。
第 23~26 行:上一节 init() 的实现仅是为了测试 crate_interface,这里重新实现。先是指定日志对象,然后设置默认日志级别 warn。
第 28~31 行:控制日志级别 set_max_level,支持关闭 off 以及 error, warn, info, debug, trace5 个级别。默认是 warn 级,即默认情况下只输出警告与错误。
然后,最重要的一步,按照 crate log 的实现要求,为 Logger 实现 trait Log 接口。这个外部的 crate log 本身是一个框架,实现了日志的各种通用功能,但是如何对日志进行输出需要基于所在的环境,这个 trait Log 就是通用功能与环境交互的接口。
下面列出实现 Log 接口的具体逻辑:
macro_rules! with_color {
($color_code:expr, $($arg:tt)*) => {{
format_args!("\u{1B}[{}m{}\u{1B}[m", $color_code as u8, format_args!($($arg)*))
}};
}
#[repr(u8)]
#[allow(dead_code)]
enum ColorCode {
Red = 31, Green = 32, Yellow = 33, Cyan = 36, White = 37, BrightBlack = 90,
}
impl Log for Logger {
#[inline]
fn enabled(&self, _metadata: &Metadata) -> bool {
true
}
fn log(&self, record: &Record) {
let level = record.level();
let line = record.line().unwrap_or(0);
let path = record.target();
let args_color = match level {
Level::Error => ColorCode::Red,
Level::Warn => ColorCode::Yellow,
Level::Info => ColorCode::Green,
Level::Debug => ColorCode::Cyan,
Level::Trace => ColorCode::BrightBlack,
};
let now = call_interface!(LogIf::get_time);
print_fmt(with_color!(
ColorCode::White,
"[{:>3}.{:06} {path}:{line}] {args}\n",
now.as_secs(),
now.subsec_micros(),
path = path,
line = line,
args = with_color!(args_color, "{}", record.args()),
));
}
fn flush(&self) {}
}第 1~11 行:为日志输出功能准备一个宏 with_color 和颜色代码,后面将根据级别为日志文本增加不同的颜色。
第 13~17 行:是否启用日志功能,硬编码启用即可。
第 19~41 行:Log::log 方法是关键,准备好显示颜色、当前时间、当前模块路径、行号以及日志内容等一系列参数,然后调用 print_fmt 执行日志的输出功能。
第 43 行:flush 刷新日志缓存。我们内核日志目前只是打印到屏幕,不涉及刷新,所以忽略。
下一步来看 print_fmt 的具体实现:
impl Write for Logger {
fn write_str(&mut self, s: &str) -> fmt::Result {
call_interface!(LogIf::write_str, s);
Ok(())
}
}
pub fn print_fmt(args: fmt::Arguments) {
let _ = Logger.write_fmt(args);
}第 1~6 行:为 Logger 实现 Write trait,目的是借助 Rust 提供的这个 trait,完成从变参到最终字符串的转换。我们只需要实现 write_str 方法,输入参数已经是处理好的结果字符串,然后通过 call_interface 调用 axhal 中实现的 LogIf::write_str 来完成日志输出。
第 8~10 行:print_fmt 的实现。既然 Logger 已经实现了 Write trait,我们只需要调用 Logger 的 write_fmt 方法,Logger 就会自动处理变参,进而如上面所述,通过 write_str 进行输出。
上面已经完成了 axlog 的实现,下面在 axruntime 中初始化 axlog,并尝试打印两行日志:
#![no_std]
pub use axhal::ax_println as println;
#[macro_use]
extern crate axlog;
#[no_mangle]
pub extern "C" fn rust_main(hartid: usize, dtb: usize) -> ! {
extern "C" {
fn _skernel();
fn main();
}
println!("\nArceOS is starting ...");
// We reserve 2M memory range [0x80000000, 0x80200000) for SBI,
// but it only occupies ~194K. Split this range in half,
// requisition the higher part(1M) for early heap.
axalloc::early_init(_skernel as usize - 0x100000, 0x100000);
axlog::init();
axlog::set_max_level(option_env!("LOG").unwrap_or(""));
info!("Logging is enabled.");
info!("Primary CPU {} started, dtb = {:#x}.", hartid, dtb);
unsafe { main(); }
loop {}
}第 22 行:初始化 axlog 组件。上节已经实现这行。
第 23 行:通过 make 传入外部环境变量 LOG,指定日志级别。
第 24~25 行:打印两行日志到屏幕。
执行 make run LOG=info 验证 axlog 是否能够完成日志初始化和 info 级别的日志输出:
ArceOS is starting ... [ 0.098586 axruntime:24] Logging is enabled. [ 0.103594 axruntime:25] Primary CPU 0 started, dtb = 0x87000000.
Now: 0.107696 Hello, ArceOS![from String] Elapsed: 0.002323
在屏幕输出中显示了我们记录的 info 日志,axlog 验证成功!
之前我们的内核已经实现了一个最简单的 panic,处理方式就是进入无限循环等待。本节来完善对它的实现。
// axhal/src/riscv64/lang_items.rs
use axlog::error;
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
error!("{}", info);
axhal::misc::terminate()
}很简单,先打印错误信息日志,然后内核中止运行。对于中止运行这个功能,我们需要扩展一下 axhal 组件。
// axhal/src/riscv64/misc.rs
pub fn terminate() -> ! {
sbi_rt::system_reset(sbi_rt::Shutdown, sbi_rt::NoReason);
loop {}
}
// axhal/src/riscv64.rs
mod misc;
pub use misc::terminate;既然有了 terminate 功能,我们把 axruntime 的 rust_main 函数最后一行 loop {},直接替换为 terminate(),如下:
// axruntime/src/lib.rs
#[no_mangle]
pub extern "C" fn rust_main(hartid: usize, dtb: usize) -> ! {
... ...
unsafe { main(); }
axhal::terminate();
}再次执行 make run,查看执行结果:
ArceOS is starting ...
Now: 0.098169 Hello, ArceOS![from String] Elapsed: 0.003439
结果显示没有变化,但是内核执行完毕后自动就退出了,不再需要 ctrl + A +X 退出 qemu,方便了以后对内核的开发测试。
第四节 组件 axdtb - 操作设备树
在第二章的第一节中,我们已经学习了如何通过 qemu 命令行,导出平台的配置信息。
这一节来到了内核在启动早期的一个重要环节,让内核自己解析 fdt 设备树来获得硬件平台的配置情况,作为后面启动过程的基础。
回顾一下,内核最初启动时从 SBI 得到两个参数分别在 a0 和 a1 寄存器中。其中 a1 寄存器保存的是 dtb 的开始地址,而 dtb 就是 fdt 的二进制形式,它的全称 device tree blob。由于它已经在内存中放置好,内核启动时就可以直接解析它的内容获取信息。
首先来了解一下标准 dtb 文件的布局规定:

我们内核要解析的 dtb 内存块实际就是 dtb 文件在内存中的映射,主要包含四个部分:
- 头结构 header:固定长度和格式,保存着全局信息和后面各个部分的相对偏移,所以解析 header 是解析整个 dtb 的第一步。
- 保留的内存区域信息:这部分我们暂时用不到。跳过。
- 主体结构:dtb 主体是由 Node 构成的树型结构,每个 Node 可以有自己的 properties。这个是我们要解析的主体,后面重点说明。
- 字符串表:一系列将被 Node 引用的字符串信息,由于每个字符串都是不定长的,所以把它们集中归置成一个块,并放到最后。
下面开始创建 axdtb 组件,首先给出解析设备树所需的常量和错误定义:
// axdtb/src/lib.rs
#![no_std]
use core::str;
use axconfig::align_up;
mod util;
pub use crate::util::SliceRead;
extern crate alloc;
use alloc::{borrow::ToOwned, string::String, vec::Vec};
const MAGIC_NUMBER : u32 = 0xd00dfeed;
const SUPPORTED_VERSION: u32 = 17;
const OF_DT_BEGIN_NODE : u32 = 0x00000001;
const OF_DT_END_NODE : u32 = 0x00000002;
const OF_DT_PROP : u32 = 0x00000003;
#[derive(Debug)]
pub enum DeviceTreeError {
BadMagicNumber,
SliceReadError,
VersionNotSupported,
ParseError(usize),
Utf8Error,
}
pub type DeviceTreeResult<T> = Result<T, DeviceTreeError>;第 13~17 行:规范对设备树文件中各个常量的定义。
第 19~28 行:解析设备树过程中需要的错误类型定义。
定义 DeviceTree 作为主类型:
// axdtb/src/lib.rs
pub struct DeviceTree {
ptr: usize,
totalsize: usize,
pub off_struct: usize,
off_strings: usize,
}
impl DeviceTree {
pub fn init(ptr: usize) -> DeviceTreeResult<Self> {
let buf = unsafe {
core::slice::from_raw_parts(ptr as *const u8, 24)
};
if buf.read_be_u32(0)? != MAGIC_NUMBER {
return Err(DeviceTreeError::BadMagicNumber)
}
if buf.read_be_u32(20)? != SUPPORTED_VERSION {
return Err(DeviceTreeError::VersionNotSupported);
}
let totalsize = buf.read_be_u32(4)? as usize;
let off_struct = buf.read_be_u32(8)? as usize;
let off_strings = buf.read_be_u32(12)? as usize;
Ok(
Self {ptr, totalsize, off_struct, off_strings}
)
}
}第 2~7 行:定义设备树的数据结构 DeviceTree,其中 ptr 和 totalsize 保持 dtb 内存块开始地址和总长度,另外两个成员分别是主体结构和字符串表的偏移。整个 DeviceTree 结构实际就对应于 dtb header。
第 10~29 行:初始化方法 init(),解析 dtb header,首先校验 magic 和版本,然后取出 header 的基本信息填充 DeviceTree 实例。
完成 header 信息解析后,后面主要的任务就是通过 off_struct 标记的偏移,解析 dtb 主体结构。前面提到,dtb 主体结构是一个由 Node 构成的树型结构,来看一下这棵树的示意图:

每一个节点 Node 由两部分组成,属性列表 properties 和子节点 Node 列表。每个属性 property 是 key - value 的形式。每个子节点重复上述的构成。从实现的角度,我们当然可以定义 Node 的数据结构,并在解析 dtb 时申请内存构建 Node 实例,如此逐渐构成一棵树,这样以后就可以随时遍历它获取目标信息。但是这种方式比较耗费内存资源,而我们内核目前只能使用 1M 的动态内存堆,所以考虑了另外一种方案:从 dtb 根节点开始,进行一次性的深度优先递归遍历,每遍历到一个节点 Node,就把它的信息传递给一个回调函数(闭包)处理。这种方案比较节省内存,并且目前不需要定义 Node 数据结构,我们在调用回调函数时,可以直接把 Node 的各个属性直接传入。
回调闭包的形式是 FnMut(String, usize, usize, Vec<(String, Vec<u8>)>,四个参数按顺序分别是节点 Node 的名称、#address-cells、#size-cells 和属性列表,每个属性都是名值对形式。关于 #address-cells 和 #size-cells,它们用于指明如何解释当前 Node 及下级 Node 的 reg 属性,在第二章第一节已经说明了它们的作用。
下面来实现解析 dtb 主体部分的方法 parse:
// axdtb/src/lib.rs
impl DeviceTree {
pub fn parse(
&self, mut pos: usize,
mut addr_cells: usize,
mut size_cells: usize,
cb: &mut dyn FnMut(String, usize, usize, Vec<(String, Vec<u8>)>)
) -> DeviceTreeResult<usize> {
let buf = unsafe {
core::slice::from_raw_parts(self.ptr as *const u8, self.totalsize)
};
// check for DT_BEGIN_NODE
if buf.read_be_u32(pos)? != OF_DT_BEGIN_NODE {
return Err(DeviceTreeError::ParseError(pos))
}
pos += 4;
let raw_name = buf.read_bstring0(pos)?;
pos = align_up(pos + raw_name.len() + 1, 4);
// First, read all the props.
let mut props = Vec::new();
while buf.read_be_u32(pos)? == OF_DT_PROP {
let val_size = buf.read_be_u32(pos+4)? as usize;
let name_offset = buf.read_be_u32(pos+8)? as usize;
// get value slice
let val_start = pos + 12;
let val_end = val_start + val_size;
let val = buf.subslice(val_start, val_end)?;
// lookup name in strings table
let prop_name = buf.read_bstring0(self.off_strings + name_offset)?;
let prop_name = str::from_utf8(prop_name)?.to_owned();
if prop_name == "#address-cells" {
addr_cells = val.read_be_u32(0)? as usize;
} else if prop_name == "#size-cells" {
size_cells = val.read_be_u32(0)? as usize;
}
props.push((prop_name, val.to_owned()));
pos = align_up(val_end, 4);
}
// Callback for parsing dtb
let name = str::from_utf8(raw_name)?.to_owned();
cb(name, addr_cells, size_cells, props);
// Then, parse all its children.
while buf.read_be_u32(pos)? == OF_DT_BEGIN_NODE {
pos = self.parse(pos, addr_cells, size_cells, cb)?;
}
if buf.read_be_u32(pos)? != OF_DT_END_NODE {
return Err(DeviceTreeError::ParseError(pos))
}
pos += 4;
Ok(pos)
}
}
impl From<str::Utf8Error> for DeviceTreeError {
fn from(_: str::Utf8Error) -> DeviceTreeError {
DeviceTreeError::Utf8Error
}
}第 4 行:参数 pos 从 off_struct 开始,跟踪当前解析到达的位置;
第 5~6 行:参数 addr_cells 和 size_cells 分别是当前节点 Node 中,地址&长度属性包含的 cells 的个数,每个 cell 是一个大端表示的 32 位数值,是拼接地址和长度的基本元素;
第 7 行:参数 cb 传入处理节点的回调闭包。在递归过程中,它保持不变一直传递下去。
第 13~15 行:确保当前正在解析的是一个 Node 节点。
第 18 行:读出当前节点的名称,并在第 41 行把它从字节串转换成字符串。
第 22~39 行:解析节点所有的属性,把他们组成属性列表。
第 42 行:调用 cb 回调函数,传入当前节点的名称、addr_cells 和 size_cells 和属性列表。这个 cb 回调函数就是 axdtb 框架与具体处理逻辑之间的接口,下一节我们通过实现它来获取我们期望的物理内存长度和 virtio 信息。
第 44~46 行:对每个子节点递归调用 parse 方法。注意发生变化的除了 pos 这个扫描位置之外,addr_cells 和 size_cells也 有可能变化,子节点如果有这两个属性,可以覆盖父节点的属性值,即局部可以在自己的域范围内覆盖上级域的配置。
解析内容时,会对 slice 调用 read_be_[u32|u64] 方法,把大端的数值转换为小端序。这个不是 slice 的标准功能,需要我们自己实现一个 trait,其中包含 read_be_u32 在内的四个附加处理方法。
// axdtb/src/util.rs
use crate::{DeviceTreeResult, DeviceTreeError};
pub trait SliceRead {
fn read_be_u32(&self, pos: usize) -> DeviceTreeResult<u32>;
fn read_be_u64(&self, pos: usize) -> DeviceTreeResult<u64>;
fn read_bstring0(&self, pos: usize) -> DeviceTreeResult<&[u8]>;
fn subslice(&self, start: usize, len: usize) -> DeviceTreeResult<&[u8]>;
}
impl<'a> SliceRead for &'a [u8] {
fn read_be_u32(&self, pos: usize) -> DeviceTreeResult<u32> {
// check size is valid
if ! (pos+4 <= self.len()) {
return Err(DeviceTreeError::SliceReadError)
}
Ok(
(self[pos] as u32) << 24
| (self[pos+1] as u32) << 16
| (self[pos+2] as u32) << 8
| (self[pos+3] as u32)
)
}
fn read_be_u64(&self, pos: usize) -> DeviceTreeResult<u64> {
let hi: u64 = self.read_be_u32(pos)?.into();
let lo: u64 = self.read_be_u32(pos+4)?.into();
Ok((hi << 32) | lo)
}
fn read_bstring0(&self, pos: usize) -> DeviceTreeResult<&[u8]> {
let mut cur = pos;
while cur < self.len() {
if self[cur] == 0 {
return Ok(&self[pos..cur])
}
cur += 1;
}
Err(DeviceTreeError::SliceReadError)
}
fn subslice(&self, start: usize, end: usize) -> DeviceTreeResult<&[u8]> {
if ! (end < self.len()) {
return Err(DeviceTreeError::SliceReadError)
}
Ok(&self[start..end])
}
}第 4~9 行:定义一个针对 slice 的新的 trait,用来处理大小端的转换。
第 11~45 行:为 slice 实现上述 trait。重点是 read_be_u32 和 read_be_u64,逆转字节序以适应我们内核的需要。
至此,axdtb 组件本身已经实现。下面来测试一下:
先建立一个用于测试的设备树文件 sample.dts,
/dts-v1/;
/ {
address-cells = <0x2>;
size-cells = <0x2>;
compatible = "riscv-virtio";
soc {
address-cells = <0x2>;
size-cells = <0x2>;
compatible = "simple-bus";
virtio_mmio@10001000 {
reg = <0x0 0x10001000 0x0 0x1000>;
compatible = "virtio,mmio";
};
};
};执行如下命令把它转化为二进制格式,我们在第二章第一节使用过该命令,只是转化方向与这里是相反的。
dtc ./sample.dts -o ./sample.dtb
编写测试用例:
// axdtb/tests/test_dtb.rs
use std::str;
use std::io::Read;
use axdtb::SliceRead;
#[test]
fn test_dtb() {
let mut input = std::fs::File::open("tests/sample.dtb").unwrap();
let mut buf = Vec::new();
input.read_to_end(&mut buf).unwrap();
let mut cb = |name: String, addr_cells: usize, size_cells: usize, props: Vec<(String, Vec<u8>)>| {
match name.as_str() {
"" => {
assert_eq!(addr_cells, 2);
assert_eq!(size_cells, 2);
for prop in &props {
if prop.0.as_str() == "compatible" {
assert_eq!(str::from_utf8(&(prop.1)), Ok("riscv-virtio\0"));
}
}
},
"soc" => {
assert_eq!(addr_cells, 2);
assert_eq!(size_cells, 2);
for prop in &props {
if prop.0.as_str() == "compatible" {
assert_eq!(str::from_utf8(&(prop.1)), Ok("simple-bus\0"));
}
}
},
"virtio_mmio@10001000" => {
assert_eq!(addr_cells, 2);
assert_eq!(size_cells, 2);
for prop in &props {
if prop.0.as_str() == "compatible" {
assert_eq!(str::from_utf8(&(prop.1)), Ok("virtio,mmio\0"));
} else if prop.0.as_str() == "reg" {
let reg = &(prop.1);
assert_eq!(reg.as_slice().read_be_u64(0).unwrap(), 0x10001000);
assert_eq!(reg.as_slice().read_be_u64(8).unwrap(), 0x1000);
}
}
},
_ => {}
}
};
let dt = axdtb::DeviceTree::init(buf.as_slice().as_ptr() as usize).unwrap();
assert_eq!(dt.parse(dt.off_struct, 0, 0, &mut cb).unwrap(), 396);
}第 12~47 行:测试用例主要是编写这个回调闭包,过滤测试文件的目标节点进行解析并验证结果。
第 49~50 行:初始化设备树对象,然后启动 parse 过程,每遇到一个节点 Node,都会自动调用上面的 cb 回调函数进行处理。
执行 make test 进行测试,成功!
第五节 基于设备树获取内存信息
下面就可以基于 axdtb 组件来解析硬件平台的设备树信息,我们首先要知道的是物理内存的上限和各个 mmio 范围。基于这两个信息,在下一章中,我们的内核将重建地址空间并建立正式的内存动态分配机制。
首先来实现解析函数 parse_dtb,从设备树中解析物理内存上限和各个 mmio 范围。
// axruntime/src/lib.rs
extern crate alloc;
use core::str;
use alloc::string::String;
use alloc::vec::Vec;
use axdtb::SliceRead;
use axconfig::phys_to_virt;
struct DtbInfo {
memory_addr: usize,
memory_size: usize,
mmio_regions: Vec<(usize, usize)>,
}
fn parse_dtb(dtb_pa: usize) -> axdtb::DeviceTreeResult<DtbInfo> {
let dtb_va = phys_to_virt(dtb_pa);
let mut memory_addr = 0;
let mut memory_size = 0;
let mut mmio_regions = Vec::new();
let mut cb = |_name: String, addr_cells: usize, size_cells: usize, props: Vec<(String, Vec<u8>)>| {
let mut is_memory = false;
let mut is_mmio = false;
let mut reg = None;
for prop in props {
match prop.0.as_str() {
"device_type" => {
is_memory = str::from_utf8(&(prop.1))
.map_or_else(|_| false, |v| v == "memory\0");
},
"compatible" => {
is_mmio = str::from_utf8(&(prop.1))
.map_or_else(|_| false, |v| v == "virtio,mmio\0");
},
"reg" => {
reg = Some(prop.1);
},
_ => (),
}
}
if is_memory {
assert!(addr_cells == 2);
assert!(size_cells == 2);
if let Some(ref reg) = reg {
memory_addr = reg.as_slice().read_be_u64(0).unwrap() as usize;
memory_size = reg.as_slice().read_be_u64(8).unwrap() as usize;
}
}
if is_mmio {
assert!(addr_cells == 2);
assert!(size_cells == 2);
if let Some(ref reg) = reg {
let addr = reg.as_slice().read_be_u64(0).unwrap() as usize;
let size = reg.as_slice().read_be_u64(8).unwrap() as usize;
mmio_regions.push((addr, size));
}
}
};
let dt = axdtb::DeviceTree::init(dtb_va.into())?;
dt.parse(dt.off_struct, 0, 0, &mut cb)?;
Ok(DtbInfo {memory_addr, memory_size, mmio_regions})
}第 10~14 行:定义返回解释结果的结构体,包括物理内存的开始地址和长度以及 virtio_mmio 地址范围列表。
第 27~42 行:设备树中,物理内存节点的 device_type 是 "memory";而 virtio_mmio 的 compatible 是 "virtio,mmio"。过滤出这两种节点,并取出它们的地址范围信息,此类信息记录在 reg 属性中。
第 43~50 行:读出物理内存的地址范围信息。
第 51~59 行:读出 VirtIO_MMIO 的地址范围信息。
第 62~63 行:从设备树的 off_struct 指向的位置开始解析。
在 axruntime 中调用 axdtb 解析平台信息,位置就在初始化日志组件 axlog 之后:
// axruntime/src/lib.rs
#[no_mangle]
pub extern "C" fn rust_main(hartid: usize, dtb: usize) -> ! {
... ...
axlog::init();
axlog::set_max_level(option_env!("LOG").unwrap_or("")); // no effect if set `log-level-*` features
info!("Logging is enabled.");
info!("Primary CPU {} started, dtb = {:#x}.", hartid, dtb);
// Parse fdt for early memory info
let dtb_info = match parse_dtb(dtb.into()) {
Ok(info) => info,
Err(err) => panic!("Bad dtb {:?}", err),
};
info!("Memory: {:#x}, size: {:#x}", dtb_info.memory_addr, dtb_info.memory_size);
info!("Virtio_mmio[{}]:", dtb_info.mmio_regions.len());
for r in &dtb_info.mmio_regions {
info!("\t{:#x}, size: {:#x}", r.0, r.1);
}
... ...
}
// axruntime/Cargo.toml
[dependencies]
axdtb = { path = "../axdtb" }
axconfig = { path = "../axconfig" }第 11~15 行:调用上面的 parse_dtb 开始扫描整个设备树,期间会触发我们注册的回调闭包。每发现一个节点,cb 就会被调用一次,从中过滤出我们需要的两组信息:一是物理内存的开始地址和总的大小,二是 virtio_mmio 范围列表。
第 17~21 行:展示从设备树中解析获得的物理内存的开始地址和长度以及 virtio_mmio 地址范围列表。
上面过程中需要调用 phys_to_virt 把 dtb 块的物理地址转换为虚拟地址,所以最后扩展一下 axconfig 的实现,增加这个地址转换函数和它对应的反向转换函数。
#[inline]
pub const fn phys_to_virt(pa: usize) -> usize {
pa.wrapping_add(PHYS_VIRT_OFFSET)
}
#[inline]
pub const fn virt_to_phys(va: usize) -> usize {
va.wrapping_sub(PHYS_VIRT_OFFSET)
}验证一下我们增加的新功能,执行 make run LOG=info。
ArceOS is starting ... [ 0.099759 axruntime:31] Logging is enabled. [ 0.107211 axruntime:32] Primary CPU 0 started, dtb = 0x87000000. [ 0.120634 axruntime:40] Memory: 0x80000000, size: 0x8000000 [ 0.121983 axruntime:41] Virtio_mmio[8]: [ 0.123077 axruntime:43] 0x10008000, size: 0x1000 [ 0.124260 axruntime:43] 0x10007000, size: 0x1000 [ 0.125612 axruntime:43] 0x10006000, size: 0x1000 [ 0.126650 axruntime:43] 0x10005000, size: 0x1000 [ 0.128103 axruntime:43] 0x10004000, size: 0x1000 [ 0.130050 axruntime:43] 0x10003000, size: 0x1000 [ 0.132008 axruntime:43] 0x10002000, size: 0x1000 [ 0.134621 axruntime:43] 0x10001000, size: 0x1000
Now: 0.135674 Hello, ArceOS![from String] Elapsed: 0.001336 [ 0.138626 axhal::riscv64::lang_items:6] panicked at axruntime/src/lib.rs:47:5: ArceOS exit ...
验证成功!可以看到取得了物理内存的开始地址及长度,还有 virtio_mmio 的各地址范围。
第六节 组件 linked_list - 侵入式链表
链表是十分常用的数据结构,从实现方式上大致可以分成两类:

- 左侧 - 普通链表:每个节点都占用独立的内存,包含指向数据块的指针 ,例如 Rust 标准库中提供的 LinkedList 类型。
- 右侧 - 侵入式链表:节点直接存在于目标数据块中,节点本身不需要单独申请内存,这种链表常用于维护空闲块。
本节我们来实现侵入式链表,它在后面内核的开发中非常重要,比如下一章中,我们就会把它作为实现 buddy 内存分配器的基础。
我们的侵入式链表的实现参考了 Sergio Benitez 的工作成果,见 CS140e
// buddy_allocator/src/linked_list.rs
#![no_std]
use core::marker::PhantomData;
use core::ptr;
#[derive(Copy, Clone)]
pub struct LinkedList {
head: *mut usize,
}
unsafe impl Send for LinkedList {}
impl LinkedList {
pub const fn new() -> LinkedList {
LinkedList {
head: ptr::null_mut(),
}
}
pub fn is_empty(&self) -> bool {
self.head.is_null()
}
}第 9 行:链表本身只有一个成员 head,它指向第一个节点,各节点之间通过指针关联。这方面仍然是典型链表的实现。
// buddy_allocator/src/linked_list.rs
impl LinkedList {
pub unsafe fn push(&mut self, item: *mut usize) {
*item = self.head as usize;
self.head = item;
}
pub fn pop(&mut self) -> Option<*mut usize> {
match self.is_empty() {
true => None,
false => {
let item = self.head;
self.head = unsafe { *item as *mut usize };
Some(item)
}
}
}
}第 3~6 行:push 操作是把新的节点插入到链表的开头。
第 7~17 行:pop 操作先处理链表空的情况;然后如果链表不空,就把第一个节点摘出并返回。
综合来看,push/pop 都是针对链表头这端,即后入先出,该链表相当于栈。
下面为链表实现只读和可修改的迭代器:
// buddy_allocator/src/linked_list.rs
impl LinkedList {
pub fn iter(&self) -> Iter {
Iter {
curr: self.head,
list: PhantomData,
}
}
pub fn iter_mut(&mut self) -> IterMut {
IterMut {
prev: &mut self.head as *mut *mut usize as *mut usize,
curr: self.head,
list: PhantomData,
}
}
}第 3~8 行:Iter 迭代器比较简单,只需要一个指向当前位置的指针。
第 9~15 行:IterMut 的迭代器,需要支持把节点弹出链表的操作,为此,除了当前位置指针,还需要前一个节点的指针 prev - 即指向当前位置指针的指针,这样通过简单的修改 prev 就能从链表中删除掉当前节点。
Iter 迭代器的实现:
// buddy_allocator/src/linked_list.rs
pub struct Iter<'a> {
curr: *mut usize,
list: PhantomData<&'a LinkedList>,
}
impl<'a> Iterator for Iter<'a> {
type Item = *mut usize;
fn next(&mut self) -> Option<Self::Item> {
if self.curr.is_null() {
None
} else {
let item = self.curr;
let next = unsafe { *item as *mut usize };
self.curr = next;
Some(item)
}
}
}IterMut 迭代器的实现:
// buddy_allocator/src/linked_list.rs
pub struct IterMut<'a> {
list: PhantomData<&'a mut LinkedList>,
prev: *mut usize,
curr: *mut usize,
}
impl<'a> Iterator for IterMut<'a> {
type Item = ListNode;
fn next(&mut self) -> Option<Self::Item> {
if self.curr.is_null() {
None
} else {
let res = ListNode {
prev: self.prev,
curr: self.curr,
};
self.prev = self.curr;
self.curr = unsafe { *self.curr as *mut usize };
Some(res)
}
}
}
pub struct ListNode {
prev: *mut usize,
curr: *mut usize,
}
impl ListNode {
pub fn pop(self) -> *mut usize {
unsafe {
*(self.prev) = *(self.curr);
}
self.curr
}
pub fn value(&self) -> *mut usize {
self.curr
}
}第 25~39 行:IterMut 迭代器需要额外定义一个辅助类型 ListNode。
现在我们可以编写一组测试用例,验证侵入式链表的功能:
#[test]
fn test_linked_list() {
let mut value1: usize = 0;
let mut value2: usize = 0;
let mut value3: usize = 0;
let mut list = linked_list::LinkedList::new();
unsafe {
list.push(&mut value1 as *mut usize);
list.push(&mut value2 as *mut usize);
list.push(&mut value3 as *mut usize);
}
assert_eq!(value3, &value2 as *const usize as usize);
assert_eq!(value2, &value1 as *const usize as usize);
assert_eq!(value1, 0);
let mut iter = list.iter();
assert_eq!(iter.next(), Some(&mut value3 as *mut usize));
assert_eq!(iter.next(), Some(&mut value2 as *mut usize));
assert_eq!(iter.next(), Some(&mut value1 as *mut usize));
assert_eq!(iter.next(), None);
let mut iter_mut = list.iter_mut();
assert_eq!(iter_mut.next().unwrap().pop(), &mut value3 as *mut usize);
assert_eq!(list.pop(), Some(&mut value2 as *mut usize));
assert_eq!(list.pop(), Some(&mut value1 as *mut usize));
assert_eq!(list.pop(), None);
}执行 make test,看到测试用例执行结果,验证成功!
本章总结
本章实现了获取系统时间、打破循环依赖、支持日志以及支持设备树解析等功能,这些基本功能为我们后面内核的开发奠定了基础。其中解析设备树以获取平台在内存方面的信息是关键,由此,我们就知道了本平台物理内存的确切范围,这将是下面一章我们的内核进行第二阶段内存管理初始化的基础;同时,也获得了设备 mmio 的信息,我们将在第九章基于这部分信息发现设备并关联驱动。
第四章 内存管理 2 - 地址空间重建和正式内存分配
在第二章里,我们学习了内核启动早期的内存管理,建立了初始的地址空间和早期的内存分配机制。由于内核在当时了解的平台信息以及它自身的能力有限,这些内存管理机制都是非常粗放和简陋的。经过了第三章的准备工作,尤其是在通过解析 dtb 获知物理内存的具体情况之后,本章我们就可以建立完整的内存管理机制。
第一节 分页机制- 支持多级页表
回顾一下第二章的第二节,当时我们实现了最基本的页表管理机制,那时还只是支持一级页表,即仅有根页表。这个根页表占用的内存页是内核预先分配的,操作时只要查出页表项的偏移,然后进行设置即可。这个单级的页表机制在管理上非常的粗放,也仅仅就是适应内核在启动的早期阶段对分页的需求。本节我们就来支持多级页表管理,一方面对虚拟地址空间进行更细粒度的控制,另一方面把设备 mmio 地址范围也映射到虚拟空间以纳入管理。
在讨论如何支持多级页表之前,我们需要先解决地址空间映射中可能遇到的对齐问题:

之前的 map 实现十分简单,只是映射了 1G,并且 va/pa 地址以及总长度 total_size 都是按 1G 对齐的。但是如果地址范围可能出现不对齐的情况,这是指开始/结束地址没有按照 best_size 对齐或者总长度就小于 best_size。例如我们期望按照 2M 的粒度进行映射(即 best_size 是 2M,如上图所示),但是起止地址都没有按照 2M 对齐,那就需要把映射范围分成三个部分:把中间按照 2M 对齐的部分截出来,按照 2M 的 best_size 进行映射;把前后两个剩余部分按照 4K 的粒度单独映射。
注:对于map方法来说,地址和长度至少是按照4K的基本页面长度对齐的,否则就是无效参数。
为了让我们的 map 方法更加通用,还需要增加一个 map_aligned 方法,由它们配合解决上面不对齐的情况。
对组件 page_table 进行扩展,首先是改造 PageTable::map(...) 方法:
// page_table/src/lib.rs
pub struct PageTable<'a> {
pub fn map(&mut self, mut va: usize, mut pa: usize,
mut total_size: usize, best_size: usize, flags: usize
) -> PagingResult {
let mut map_size = best_size;
if total_size < best_size {
map_size = PAGE_SIZE;
}
let offset = align_offset(va, map_size);
if offset != 0 {
assert!(map_size != PAGE_SIZE);
let offset = map_size - offset;
self.map_aligned(va, pa, offset, PAGE_SIZE, flags)?;
va += offset;
pa += offset;
total_size -= offset;
}
let aligned_total_size = align_down(total_size, map_size);
total_size -= aligned_total_size;
let ret = self.map_aligned(va, pa, aligned_total_size, map_size, flags)?;
if total_size != 0 {
va += aligned_total_size;
pa += aligned_total_size;
self.map_aligned(va, pa, total_size, PAGE_SIZE, flags)
} else {
ret
}
}
}第 6~9 行:如果映射范围总长度小于 best_size,后面都直接按照 4K 页粒度映射。
第 10~18 行:如果地址范围的头部存在不对齐的部分,先按 4K 页粒度映射。
第 20~22 行:调用 map_aligned 方法按照 best_size 进行映射。
第 24~26 行:如果还存在剩余部分尚未映射,那这部分也是未对齐的部分,按照 4K 页粒度映射。
然后看一下新增的辅助方法 map_aligned 的实现,它在很大程度上继承了旧版 map 方法的逻辑:
// page_table/src/lib.rs
pub struct PageTable<'a> {
fn map_aligned(&mut self, mut va: usize, mut pa: usize,
mut total_size: usize, best_size: usize, flags: usize
) -> PagingResult {
assert!(is_aligned(va, best_size));
assert!(is_aligned(pa, best_size));
assert!(is_aligned(total_size, best_size));
let entry_size = self.entry_size();
let next_size = min(entry_size, total_size);
while total_size >= next_size {
let index = self.entry_index(va);
if entry_size == best_size {
self.table[index].set(pa, flags);
} else {
let mut pt = self.next_table_mut(index)?;
pt.map(va, pa, next_size, best_size, flags)?;
}
total_size -= next_size;
va += next_size;
pa += next_size;
}
Ok(())
}
}第 6~8 行:检查映射范围的虚拟/物理地址以及总长度是否对 best_size 对齐。
第 9 行:当前级别上,每个 entry 对应的地址范围长度。例如对于 Sv39 的顶级页表(level 0),它的 entry 长度就是 1G。
第 10 行:如果要求映射的总长度比当前级别页表的 entry 长度还小,那么映射就不会发生在本级页表,那将在下一级甚至更低级的页表上发生,所以这个代表映射步长的 next_size 需要取 entry_size 和 total_size 的最小值。
第 11~22 行:以 next_size 为步长,为当前页表的每一个页表项 entry 建立映射。这里有两种情况:一是期望在本级完成映射,按照第 14 行的方式直接设置 entry;二是要求在更低级别的页表上建立映射,那么首先要获得下级页表的引用,然后递归调用 map 方法去建立映射。
取得下级页表有两个方法 next_table_mut 和 next_table,它们的区别是前者在页表不存在时,将会动态申请内存页创建页表。
// page_table/src/lib.rs
pub struct PageTable<'a> {
fn next_table_mut(&mut self, index: usize) -> PagingResult<PageTable> {
if self.table[index].is_unused() {
let table = Self::alloc_table(self.level + 1);
self.table[index].set(table.root_paddr(), PAGE_TABLE);
Ok(table)
} else {
self.next_table(index)
}
}
pub fn next_table(&self, index: usize) -> PagingResult<PageTable> {
assert!(self.table[index].is_present());
let pa = self.table[index].paddr();
let va = phys_to_virt(pa);
Ok(Self::init(va, self.level + 1))
}
pub fn alloc_table(level: usize) -> Self {
let layout = Layout::from_size_align(PAGE_SIZE, PAGE_SIZE).unwrap();
let ptr = unsafe { alloc::alloc::alloc_zeroed(layout) };
Self::init(ptr as usize, level)
}
pub fn root_paddr(&self) -> usize {
virt_to_phys(self.table.as_ptr() as usize)
}
pub fn entry_at(&self, index: usize) -> PTEntry {
self.table[index]
}
}第 18~22 行:负责创建页表,基于 Rust 标准的 alloc 方法先申请一页,注意长度和对齐都是 PAGE_SIZE 即 4K。
最后补充一下新增的对外部 crate 的引用和对页表项的扩展:
// page_table/src/lib.rs
#![no_std]
use core::cmp::min;
use core::alloc::Layout;
use axconfig::{PAGE_SHIFT, PAGE_SIZE, ASPACE_BITS};
use axconfig::{is_aligned, align_offset, align_down};
use axconfig::{phys_to_virt, virt_to_phys, pfn_phys};
extern crate alloc;
impl PTEntry {
fn is_present(&self) -> bool {
(self.0 as usize & _PAGE_V) == _PAGE_V
}
fn is_unused(&self) -> bool {
self.0 == 0
}
pub fn paddr(&self) -> usize {
pfn_phys(self.0 as usize >> PAGE_PFN_SHIFT)
}
pub fn flags(&self) -> usize {
self.0 as usize & ((1 << PAGE_PFN_SHIFT) - 1)
}
}现在多级页表的功能实现完毕,下面通过一个测试用例来验证我们的实现:
// page_table/tests/test_final.rs
use axconfig::SIZE_2M;
use page_table::{PageTable, PAGE_KERNEL_RWX};
#[test]
fn test_final() {
let final_pgd: [u64; 512] = [0; 512];
let mut pgd: PageTable = PageTable::init(final_pgd.as_ptr() as usize, 0);
let _ = pgd.map(0xffff_ffc0_8020_a000, 0x8020_a000, 0x7df6000, SIZE_2M, PAGE_KERNEL_RWX);
let pgd_index = pgd.entry_index(0xffff_ffc0_8020_a000);
assert_eq!(pgd_index, 258);
let pmd = pgd.next_table(pgd_index).unwrap();
let pmd_index = pmd.entry_index(0xffff_ffc0_8020_a000);
assert_eq!(pmd_index, 1);
let pt = pmd.next_table(pmd_index).unwrap();
let pt_index = pt.entry_index(0xffff_ffc0_8020_a000);
assert_eq!(pt_index, 10);
assert_eq!(pt.entry_at(pt_index).paddr(), 0x8020_a000);
assert_eq!(pt.entry_at(pt_index).flags(), PAGE_KERNEL_RWX);
}执行测试 make test,查看所有测试用例执行结果,全部通过!
第二节 重建地址空间
上一节建立了对多级页表动态映射的支持,让我们具备了更强大的管理地址空间的能力,这一节就开始重建内核的地址空间。
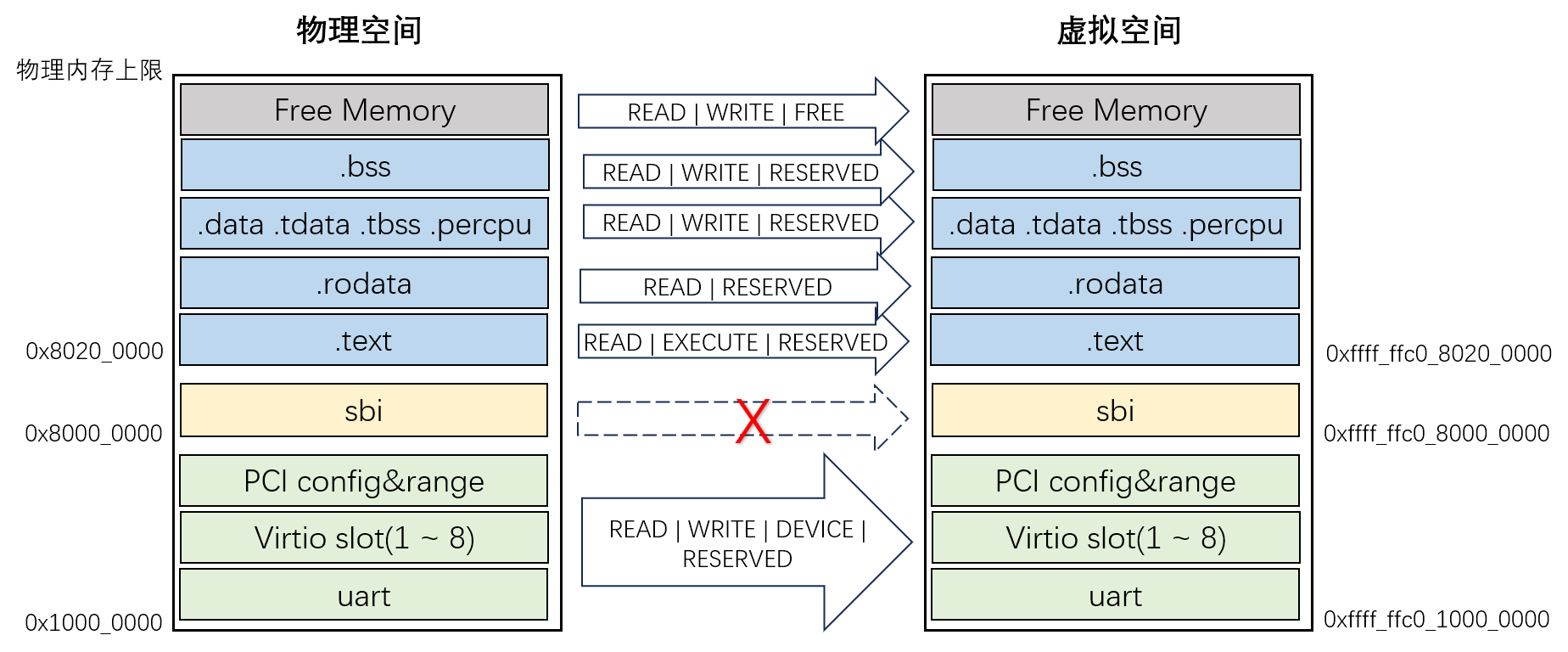
对照第二章第一节建立的虚拟地址空间,重建后的虚拟地址空间有几个主要的变化。
-
SBI 被从映射中去除了。SBI 相当于上一级的 bootloader,我们的内核必须通过 SBI 提供的 sbi_ecall 来调用它的功能,不应该看到 SBI 在地址空间中的映射区间。
-
内核本身的各个段,按照段的特点属性,进行精细化的映射。例如代码段 .text 的权限是只读和执行,而数据段 .data 就是读写。
-
内核自身空间之上的所有空闲区间,作为内核的堆空间,堆空间的上限是物理内存最高地址,上一章已经通过解析 dtb 获得。
-
建立对设备地址区间的映射,主要是 virtio-mmio 各地址区间,为后面内核进行设备的发现与管理做准备。
其中,上面第 1 条在重映射过程中忽略 SBI 占据区间即可;对第 2、第 3 和第 4,我们先定义好它们对应的一组地址区间,再进行重映射。
地址区间的数据结构 MemRegion 包括四个成员,分别是(物理)起始地址,长度,映射属性和显示名:
// axhal/src/riscv64/mem.rs
use axconfig::{virt_to_phys, align_up, align_down, PAGE_SIZE};
use page_table::{PAGE_KERNEL_RO, PAGE_KERNEL_RW, PAGE_KERNEL_RX};
#[derive(Debug)]
pub struct MemRegion {
pub paddr: usize,
pub size: usize,
pub flags: usize,
pub name: &'static str,
}
// axhal/src/riscv64.rs
pub mod mem;
mod paging;
pub use paging::write_page_table_root;表示内核段的地址区间列表:
// axhal/src/riscv64/mem.rs
pub fn kernel_image_regions() -> impl Iterator<Item = MemRegion> {
[
MemRegion {
paddr: virt_to_phys((_stext as usize).into()),
size: _etext as usize - _stext as usize,
flags: PAGE_KERNEL_RX,
name: ".text",
},
MemRegion {
paddr: virt_to_phys((_srodata as usize).into()),
size: _erodata as usize - _srodata as usize,
flags: PAGE_KERNEL_RO,
name: ".rodata",
},
MemRegion {
paddr: virt_to_phys((_sdata as usize).into()),
size: _edata as usize - _sdata as usize,
flags: PAGE_KERNEL_RW,
name: ".data .tdata .tbss .percpu",
},
MemRegion {
paddr: virt_to_phys(_skernel as usize) - 0x100000,
size: 0x100000,
flags: PAGE_KERNEL_RW,
name: "early heap",
},
MemRegion {
paddr: virt_to_phys((boot_stack as usize).into()),
size: boot_stack_top as usize - boot_stack as usize,
flags: PAGE_KERNEL_RW,
name: "boot stack",
},
MemRegion {
paddr: virt_to_phys((_sbss as usize).into()),
size: _ebss as usize - _sbss as usize,
flags: PAGE_KERNEL_RW,
name: ".bss",
},
]
.into_iter()
}
extern "C" {
fn _skernel();
fn _stext();
fn _etext();
fn _srodata();
fn _erodata();
fn _sdata();
fn _edata();
fn _sbss();
fn _ebss();
fn _ekernel();
fn boot_stack();
fn boot_stack_top();
}再看一下空闲内存区间:
// axhal/src/riscv64/mem.rs
pub fn free_regions(phys_mem_size: usize) -> impl Iterator<Item = MemRegion> {
let start = align_up(virt_to_phys(_ekernel as usize), PAGE_SIZE);
let size = _skernel as usize + phys_mem_size - _ekernel as usize;
core::iter::once(MemRegion {
paddr: start,
size: align_down(size, PAGE_SIZE),
flags: PAGE_KERNEL_RW,
name: "free memory",
})
}空闲内存区间的开始地址是 _ekernel,即内核本身占用空间的上限;而计算该区间的上限需要通过 phys_mem_size - 从 dtb 中解析获得的当前平台物理内存的大小。
下面我们将在 axruntime 的启动过程中,调用 remap_kernel_memory 进行重映射,位置就在解析和展示 dtb 信息的后面。
// axruntime/src/lib.rs
use axconfig::{phys_to_virt, SIZE_2M};
use axhal::mem::{MemRegion, kernel_image_regions, free_regions};
use axsync::BootOnceCell;
use page_table::{PAGE_KERNEL_RW, PageTable};
pub extern "C" fn rust_main(hartid: usize, dtb: usize) -> ! {
... ...
info!("Memory: {:#x}, size: {:#x}", dtb_info.memory_addr, dtb_info.memory_size);
info!("Virtio_mmio[{}]:", dtb_info.mmio_regions.len());
for r in &dtb_info.mmio_regions {
info!("\t{:#x}, size: {:#x}", r.0, r.1);
}
info!("Initialize kernel page table...");
remap_kernel_memory(dtb_info);
... ...
}
fn remap_kernel_memory(dtb: DtbInfo) {
let mmio_regions = dtb.mmio_regions.iter().map(|reg| MemRegion {
paddr: reg.0.into(),
size: reg.1,
flags: PAGE_KERNEL_RW,
name: "mmio",
});
let regions = kernel_image_regions()
.chain(free_regions(dtb.memory_size))
.chain(mmio_regions);
let mut kernel_page_table = PageTable::alloc_table(0);
for r in regions {
let _ = kernel_page_table.map(
phys_to_virt(r.paddr),
r.paddr,
r.size,
SIZE_2M,
r.flags,
);
}
static KERNEL_PAGE_TABLE: BootOnceCell<PageTable> = BootOnceCell::new();
KERNEL_PAGE_TABLE.init(kernel_page_table);
unsafe {
axhal::write_page_table_root(KERNEL_PAGE_TABLE.get().root_paddr())
};
}
// axruntime/Cargo.toml
[dependencies]
axsync = { path = "../axsync" }
page_table = { path = "../page_table" }第 47 行:重置根页表,启用新的地址空间。需要在 axhal 中实现这个 write_page_table_root 方法。
增加 write_page_table_root 方法,同时简化 init_mmu 方法。
// axhal/src/riscv64/paging.rs
pub unsafe fn init_mmu() {
write_page_table_root(boot_page_table as usize);
}
pub unsafe fn write_page_table_root(pa: usize) {
satp::set(satp::Mode::Sv39, 0, phys_pfn(pa));
riscv::asm::sfence_vma_all();
}至此,我们为内核建立了完整的地址空间。
执行 make run LOG=info 进行测试,依然正常显示,结果与之前相同,地址空间切换成功!
(待补充)附加实验:增加测试用例,访问 SBI 空间,写 text 范围,这些违规操作应当触发异常;读 mmio 的地址范围典型值,验证。
第三节 bitmap 位分配器
(待确定)看看 [rust_index::bit_set] 能否直接引入,用于简化 bitmap 的实现。
在各种内存分配的实现方式中,基于 bitmap 数据结构来表示和管理内存块,是相对简单直接的一种。我们可以用每一位 bit 来代表一个内存块,通常 1 表示空闲可用,0 表示已分配;内存块的大小可以根据需要设定,粒度小到字节 byte,大到页面 page。
这一节我们实现一个 bitmap 位分配器,下一步它将作为正式的页分配器的核心,管理内存页的分配与释放。位分配器默认配置 1M 个位,每个位代表一个页(4K 字节),这样下节的页内存分配器可管理的内存总量就是:
1M * 4K = 4G
这足以支持我们内核的需要了。
出于对效率的考虑,我们进一步把这 1M 位以嵌套的方式进行层级化管理,形成若干级 bitmap,每一级 bitmap 包含 16 位,如图:

从上往下,第 1 级只有一个 bitmap,它每一位指向第 2 级的一个 bitmap,共 16 个;如此嵌套,直至最底层 leaf level,leaf level 对应 1M 位,所以包括 64K 个 bitmap(1M / 16 = 64K)。进一步来说,每一级的 bitmap 的 bit 位对应管理着不同数量的连续页空间,第 1 级 bitmap 的一个 bit 位代表 64K 个连续页(1M / 16 = 64K),而最底层 leaf level 上每个 bitmap 的每个 bit 位仅对应一个页。
当搜索空闲页面时,只需要从上向下逐级递归查找,如果发现一个位是 0 时,就说明它对应的连续页空间已经被完全占用,不必再递归下一级,直接查看下一个位;否则说明其下对应的范围内还有空闲页,需要递归进去进一步查找和确认。
创建新组件 bitmap_allocator,核心数据结构的定义:
#![no_std]
use bit_field::BitField;
use core::ops::Range;
// bitmap_allocator/src/lib.rs
pub type BitAlloc1M = BitAllocCascade16<BitAlloc64K>;
pub type BitAlloc64K = BitAllocCascade16<BitAlloc4K>;
pub type BitAlloc4K = BitAllocCascade16<BitAlloc256>;
pub type BitAlloc256 = BitAllocCascade16<BitAlloc16>;
#[derive(Default)]
pub struct BitAllocCascade16<T: BitAlloc> {
bitset: u16, // for each bit, 1 indicates available, 0 indicates inavailable
sub: [T; 16],
}
#[derive(Default)]
pub struct BitAlloc16(u16);
// bitmap_allocator/Cargo.toml
[dependencies]
bit_field = "0.10"我们需要的是包含 1M 个位的 BitAlloc1M,包括它自己共由 5 级 bitmap 嵌套构成。最基础的元素是 BitAlloc16,包含 16 个位。
每一级的 bitmap 都实现了相同的 trait BitAlloc,以简化实现:
// bitmap_allocator/src/lib.rs
pub trait BitAlloc: Default {
/// The bitmap has a total of CAP bits, numbered from 0 to CAP-1 inclusively.
const CAP: usize;
const DEFAULT: Self;
fn alloc(&mut self) -> Option<usize>;
fn alloc_contiguous(&mut self, size: usize, align_log2: usize) -> Option<usize>;
fn next(&self, key: usize) -> Option<usize>;
fn dealloc(&mut self, key: usize);
fn insert(&mut self, range: Range<usize>);
fn remove(&mut self, range: Range<usize>);
fn is_empty(&self) -> bool;
fn test(&self, key: usize) -> bool;
}其中比较重要的是 insert(...),alloc(...) 和 alloc_contiguous(...) 三个方法。bitmap 初始化时,所有位都是 0,表示没有可用的空间,而 insert 负责按照空闲空间的位置插入 1。另两个分别是单个页和连续页的分配方法。
我们需要对 BitAllocCascade16 和 BitAlloc16 分别实现这个 trait:
// bitmap_allocator/src/lib.rs
impl<T: BitAlloc> BitAlloc for BitAllocCascade16<T> {
const CAP: usize = T::CAP * 16;
const DEFAULT: Self = BitAllocCascade16 {
bitset: 0,
sub: [T::DEFAULT; 16],
};
fn alloc(&mut self) -> Option<usize> {
if !self.is_empty() {
let i = self.bitset.trailing_zeros() as usize;
let res = self.sub[i].alloc().unwrap() + i * T::CAP;
self.bitset.set_bit(i, !self.sub[i].is_empty());
Some(res)
} else {
None
}
}
fn alloc_contiguous(&mut self, size: usize, align_log2: usize) -> Option<usize> {
if let Some(base) = find_contiguous(self, Self::CAP, size, align_log2) {
self.remove(base..base + size);
Some(base)
} else {
None
}
}
fn dealloc(&mut self, key: usize) {
let i = key / T::CAP;
self.sub[i].dealloc(key % T::CAP);
self.bitset.set_bit(i, true);
}
fn insert(&mut self, range: Range<usize>) {
self.for_range(range, |sub: &mut T, range| sub.insert(range));
}
fn remove(&mut self, range: Range<usize>) {
self.for_range(range, |sub: &mut T, range| sub.remove(range));
}
fn is_empty(&self) -> bool {
self.bitset == 0
}
fn test(&self, key: usize) -> bool {
self.sub[key / T::CAP].test(key % T::CAP)
}
fn next(&self, key: usize) -> Option<usize> {
let idx = key / T::CAP;
(idx..16).find_map(|i| {
if self.bitset.get_bit(i) {
let key = if i == idx { key - T::CAP * idx } else { 0 };
self.sub[i].next(key).map(|x| x + T::CAP * i)
} else {
None
}
})
}
}
impl<T: BitAlloc> BitAllocCascade16<T> {
fn for_range(&mut self, range: Range<usize>, f: impl Fn(&mut T, Range<usize>)) {
let Range { start, end } = range;
assert!(start <= end);
assert!(end <= Self::CAP);
for i in start / T::CAP..=(end - 1) / T::CAP {
let begin = if start / T::CAP == i { start % T::CAP } else { 0 };
let end = if end / T::CAP == i { end % T::CAP } else { T::CAP };
f(&mut self.sub[i], begin..end);
self.bitset.set_bit(i, !self.sub[i].is_empty());
}
}
}对于 BitAlloc16 的实现:
// bitmap_allocator/src/lib.rs
impl BitAlloc for BitAlloc16 {
const CAP: usize = u16::BITS as usize;
const DEFAULT: Self = Self(0);
fn alloc(&mut self) -> Option<usize> {
let i = self.0.trailing_zeros() as usize;
if i < Self::CAP {
self.0.set_bit(i, false);
Some(i)
} else {
None
}
}
fn alloc_contiguous(&mut self, size: usize, align_log2: usize) -> Option<usize> {
if let Some(base) = find_contiguous(self, Self::CAP, size, align_log2) {
self.remove(base..base + size);
Some(base)
} else {
None
}
}
fn dealloc(&mut self, key: usize) {
assert!(!self.test(key));
self.0.set_bit(key, true);
}
fn insert(&mut self, range: Range<usize>) {
self.0.set_bits(range.clone(), 0xffff.get_bits(range));
}
fn remove(&mut self, range: Range<usize>) {
self.0.set_bits(range, 0);
}
fn is_empty(&self) -> bool {
self.0 == 0
}
fn test(&self, key: usize) -> bool {
self.0.get_bit(key)
}
fn next(&self, key: usize) -> Option<usize> {
(key..Self::CAP).find(|&i| self.0.get_bit(i))
}
}另外,对于连续分配的方法 alloc_contiguous(...),需要一个辅助函数:
pub fn find_contiguous(
ba: &impl BitAlloc,
capacity: usize,
size: usize,
align_log2: usize,
) -> Option<usize> {
if capacity < (1 << align_log2) || ba.is_empty() {
return None;
}
let mut base = 0;
let mut offset = base;
while offset < capacity {
if let Some(next) = ba.next(offset) {
if next != offset {
// it can be guarenteed that no bit in (offset..next) is free
// move to next aligned position after next-1
assert!(next > offset);
base = (((next - 1) >> align_log2) + 1) << align_log2;
assert_ne!(offset, next);
offset = base;
continue;
}
} else {
return None;
}
offset += 1;
if offset - base == size {
return Some(base);
}
}
None
}现在 bitmap 位分配器实现完成,它的核心就是对 bit 位的管理,我们来写几个测试用例验证一下这方面的功能:
// bitmap_allocator/tests/test_bitalloc.rs
use bitmap_allocator::*;
#[test]
fn bitalloc16() {
let mut ba = BitAlloc16::default();
assert_eq!(BitAlloc16::CAP, 16);
ba.insert(0..16);
for i in 0..16 {
assert!(ba.test(i));
}
ba.remove(2..8);
assert_eq!(ba.alloc(), Some(0));
assert_eq!(ba.alloc(), Some(1));
assert_eq!(ba.alloc(), Some(8));
ba.dealloc(0);
ba.dealloc(1);
ba.dealloc(8);
assert!(!ba.is_empty());
for _ in 0..10 {
assert!(ba.alloc().is_some());
}
assert!(ba.is_empty());
assert!(ba.alloc().is_none());
}
#[test]
fn bitalloc4k() {
let mut ba = BitAlloc4K::default();
assert_eq!(BitAlloc4K::CAP, 4096);
ba.insert(0..4096);
for i in 0..4096 {
assert!(ba.test(i));
}
ba.remove(2..4094);
for i in 0..4096 {
assert_eq!(ba.test(i), !(2..4094).contains(&i));
}
assert_eq!(ba.alloc(), Some(0));
assert_eq!(ba.alloc(), Some(1));
assert_eq!(ba.alloc(), Some(4094));
ba.dealloc(0);
ba.dealloc(1);
ba.dealloc(4094);
assert!(!ba.is_empty());
for _ in 0..4 {
assert!(ba.alloc().is_some());
}
assert!(ba.is_empty());
assert!(ba.alloc().is_none());
}
#[test]
fn bitalloc_contiguous() {
let mut ba0 = BitAlloc16::default();
ba0.insert(0..BitAlloc16::CAP);
ba0.remove(3..6);
assert_eq!(ba0.next(0), Some(0));
assert_eq!(ba0.alloc_contiguous(1, 1), Some(0));
assert_eq!(find_contiguous(&ba0, BitAlloc4K::CAP, 2, 0), Some(1));
let mut ba = BitAlloc4K::default();
assert_eq!(BitAlloc4K::CAP, 4096);
ba.insert(0..BitAlloc4K::CAP);
ba.remove(3..6);
assert_eq!(ba.next(0), Some(0));
assert_eq!(ba.alloc_contiguous(1, 1), Some(0));
assert_eq!(ba.next(0), Some(1));
assert_eq!(ba.next(1), Some(1));
assert_eq!(ba.next(2), Some(2));
assert_eq!(find_contiguous(&ba, BitAlloc4K::CAP, 2, 0), Some(1));
assert_eq!(ba.alloc_contiguous(2, 0), Some(1));
assert_eq!(ba.alloc_contiguous(2, 3), Some(8));
ba.remove(0..4096 - 64);
assert_eq!(ba.alloc_contiguous(128, 7), None);
assert_eq!(ba.alloc_contiguous(7, 3), Some(4096 - 64));
ba.insert(321..323);
assert_eq!(ba.alloc_contiguous(2, 1), Some(4096 - 64 + 8));
assert_eq!(ba.alloc_contiguous(2, 0), Some(321));
assert_eq!(ba.alloc_contiguous(64, 6), None);
assert_eq!(ba.alloc_contiguous(32, 4), Some(4096 - 48));
for i in 0..4096 - 64 + 7 {
ba.dealloc(i);
}
for i in 4096 - 64 + 8..4096 - 64 + 10 {
ba.dealloc(i);
}
for i in 4096 - 48..4096 - 16 {
ba.dealloc(i);
}
}执行 make test,所有测试用例通过!
第四节 启用页内存分配器
上一节我们实现了一个 bitmap 位分配器,其中每个位可以对应管理一个页。本节就对其进行封装,实现一个正式的页内存分配器,用于在内核启动的后期取代早期页分配器的功能,管理内核所有的空闲内存。
首先是封装上节的 bitmap 位分配器,实现可以与 axalloc 组件的框架相适应的页内存分配器 BitmapPageAllocator:
//axalloc/src/bitmap.rs
use core::ptr::NonNull;
use crate::{AllocError, AllocResult};
use axconfig::PAGE_SIZE;
use bitmap_allocator::{BitAlloc1M, BitAlloc};
use alloc::alloc::Layout;
pub struct BitmapPageAllocator {
base: usize,
inner: BitAlloc1M,
}
impl BitmapPageAllocator {
pub const fn new() -> Self {
Self { base: 0, inner: BitAlloc1M::DEFAULT }
}
pub fn init(&mut self, start: usize, size: usize) {
let end = axconfig::align_down(start + size, PAGE_SIZE);
let start = axconfig::align_up(start, PAGE_SIZE);
self.base = start;
let total_pages = (end - start) / PAGE_SIZE;
self.inner.insert(0..total_pages);
}
}
// axalloc/Cargo.toml
[dependencies]
bitmap_allocator = { path = "../bitmap_allocator" }第 8~11 行:定义 BitmapPageAllocator,其中 inner 就是被封装的 bitmap 位分配器。
第 17~23 行:把内存地址范围换算成以页为单位,每个页对应 1 位,然后就可以利用内嵌的位分配管理器来标记页的分配情况。默认所有位初始都是 0,表示页面不可分配。第 22 行的 insert 设置了一系列连续的 1,标记这些位对应的页面是可以分配的。
然后为 BitmapPageAllocator 实现分配和释放的方法:
impl BitmapPageAllocator {
pub fn alloc_pages(&mut self, layout: Layout) -> AllocResult<NonNull<u8>> {
if layout.align() % PAGE_SIZE != 0 {
return Err(AllocError::InvalidParam);
}
let align_pow2 = layout.align() / PAGE_SIZE;
if !align_pow2.is_power_of_two() {
return Err(AllocError::InvalidParam);
}
let num_pages = layout.size() / PAGE_SIZE;
let align_log2 = align_pow2.trailing_zeros() as usize;
match num_pages.cmp(&1) {
core::cmp::Ordering::Equal => self.inner.alloc().map(|idx| idx * PAGE_SIZE + self.base),
core::cmp::Ordering::Greater => self
.inner
.alloc_contiguous(num_pages, align_log2)
.map(|idx| idx * PAGE_SIZE + self.base),
_ => return Err(AllocError::InvalidParam),
}
.map(|pos| NonNull::new(pos as *mut u8).unwrap())
.ok_or(AllocError::NoMemory)
}
pub fn dealloc_pages(&mut self, pos: usize, num_pages: usize) {
let idx = (pos - self.base) / PAGE_SIZE;
for i in 0..num_pages {
self.inner.dealloc(idx+i)
}
}
}第 12~19 行:分配的关键,如果申请一页,就直接调用位管理器的 alloc() 把对应位置的位清零,标记已分配;申请连续的多页时,则调用 alloc_contiguous() 把对应的连续位集合清零,标记它们已经分配。
第 23~27 行:释放回收页面时,先算出页面对应的第一个位的索引,从它开始逐个设置 1,标记它们已经被回收,恢复可分配状态。
目前 bitmap 页分配器已经准备好,下面把它集成到全局分配器框架中:
// axalloc/src/lib.rs
use axsync::BootOnceCell;
mod bitmap;
use bitmap::BitmapPageAllocator;
struct GlobalAllocator {
early_alloc: SpinRaw<EarlyAllocator>,
page_alloc: SpinRaw<BitmapPageAllocator>,
finalized: BootOnceCell<bool>,
}
impl GlobalAllocator {
pub const fn new() -> Self {
Self {
early_alloc: SpinRaw::new(EarlyAllocator::uninit_new()),
page_alloc: SpinRaw::new(BitmapPageAllocator::new()),
finalized: BootOnceCell::new(),
}
}
}第 9~10 行:在 GlobalAllocator 中增加 page_alloc 和 finalized,前者是正式的页内存分配器,后者区分是否处于内核的早期启动阶段,早期使用 early 分配器,后期则替换为正式的内存分配器。
基于 finalized 标记的阶段,扩展 GlobalAllocator 框架分配和释放页面的方法:
// axalloc/src/lib.rs
impl GlobalAllocator {
fn alloc_pages(&self, layout: Layout) -> *mut u8 {
let ret = if self.finalized.is_init() {
self.page_alloc.lock().alloc_pages(layout)
} else {
self.early_alloc.lock().alloc_pages(layout)
};
if let Ok(ptr) = ret {
ptr.as_ptr()
} else {
alloc::alloc::handle_alloc_error(layout)
}
}
fn dealloc_pages(&self, ptr: *mut u8, layout: Layout) {
if self.finalized.is_init() {
self.page_alloc.lock().dealloc_pages(ptr as usize, layout.size()/PAGE_SIZE)
} else {
unimplemented!()
};
}
}第 4 行:在分配方法中,根据成员 finalized 确定当前是什么阶段,早期使用 early_alloc,后期使用 page_alloc。
第 17 行:类似的,在回收的方法中同样需要检查 finalized,只有后期才需要基于 page_alloc 实现。
然后,实现 final_init() 函数,它负责启用正式的内存分配器:
// axalloc/src/lib.rs
pub fn final_init(start: usize, len: usize) {
GLOBAL_ALLOCATOR.final_init(start, len)
}
impl GlobalAllocator {
pub fn final_init(&self, start: usize, size: usize) {
self.page_alloc.lock().init(start, size);
self.finalized.init(true);
}
}第 8~9 行:final_init() 需要完成两项具体工作,初始化 page_alloc 页内存分配器,再标识 finalized 为 true,说明进入正式的内存分配器的使用阶段。从上面的 alloc_pages 和 dealloc_pages 方法可以看到,设置该标识之后,早期内存分配器被禁用,切换到正式内存分配器。
实际上本节只是处理了页内存分配器,下节会扩展 final_init() 等方法,继续处理字节内存分配器。
万事俱备,现在就来调用 final_init(),实施内存分配器的切换:
// axruntime/src/lib.rs
pub extern "C" fn rust_main(hartid: usize, dtb: usize) -> ! {
... ...
let phys_memory_size = dtb_info.memory_size;
info!("Initialize kernel page table...");
remap_kernel_memory(dtb_info);
info!("Initialize formal allocators ...");
for r in free_regions(phys_memory_size) {
axalloc::final_init(phys_to_virt(r.paddr), r.size);
}
unsafe { main(); }
axhal::terminate();
}第 4 行:预先保存物理内存的大小,因为按照 Rust 语法,remap_kernel_memory() 会 move 那个 dtb_info 变量。
第 10~12 行:遍历所有的空闲内存区域,对每一个调用 final_init,由此启用正式的内存分配器。
最后,在 axorigin 应用组件中申请页面,验证正式的内存分配器的功能:
// axorigin/src/main.rs
#![no_std]
#![no_main]
use axstd::{String, println, time, PAGE_SIZE};
#[no_mangle]
pub fn main(_hartid: usize, _dtb: usize) {
let now = time::Instant::now();
println!("\nNow: {}", now);
let s = String::from("from String");
println!("Hello, ArceOS![{}]", s);
try_alloc_pages();
let d = now.elapsed();
println!("Elapsed: {}.{:06}", d.as_secs(), d.subsec_micros());
}
fn try_alloc_pages() {
use core::alloc::Layout;
extern crate alloc;
const NUM_PAGES: usize = 300;
let layout = Layout::from_size_align(NUM_PAGES*PAGE_SIZE, PAGE_SIZE).unwrap();
let p = unsafe { alloc::alloc::alloc(layout) };
println!("Allocate pages: [{:?}].", p);
unsafe { alloc::alloc::dealloc(p, layout) };
println!("Release pages ok!");
}第 21~31 行:申请 300 个页面,然后释放。早期内存分配器的最大分配能力只有 1M,承担不了申请 300 个页面的任务(300*4K),如果分配成功,可以从侧面证明,内核已经切换到分配能力更强的正式内存分配器。
另外,应用 axorigin 调用了 PAGE_SIZE 这个常量,我们需要扩展一下 axstd,引出该常量。
// axstd/Cargo.toml
[dependencies]
axconfig = { path = "../axconfig" }
// axstd/src/lib.rs
pub use axconfig::PAGE_SIZE;现在来测试一下我们的最新成果,make run,看到 axorigin 正常申请了 300 个页面然后释放:
ArceOS is starting ...
Now: 0.114120 Hello, ArceOS![from String] Allocate pages: [0xffffffc08026c000]. Release pages ok! Elapsed: 0.006793
正式的 bitmap 页分配器已经成功启用!
第五节 实现字节内存分配器
上节我们完成了从早期的页分配器到正式页分配器的切换,下面来处理字节分配器,我们将基于经典的伙伴算法(buddy)实现这个内存分配器。关于伙伴算法,简单来说,一个内存块可以分成对等大小、地址连续的两个内存块,它们称为伙伴。当进行内存分配时,如果没有正好符合要求的空闲内存块,则需要对更大的空闲内存块逐级平分,直到划分出符合要求的最小内存块;内存释放时,尝试与它的伙伴进行合并,直至不能合并为止。这个算法兼顾了分配速度和碎片化问题。它的实现原理如下图所示:

从图中可见,buddy 内存分配器的实现结构简单,就是通过数组 + 链表来维护空闲的内存块。
数组索引称 Order,每个 Order 维护一组具有相同大小的空闲内存块,它们通过链表结构连接在一起。Order 与本级所维护的空闲块大小的对应关系:空闲块大小 = 2^order^ 字节。在分配时,每一级 Order 上的内存块都可以平分为一对伙伴内存块,挂到更低一级的 Order 链表上;反之在释放内存块时,查看它的伙伴内存块是否也是空闲,如果是则合并成上一级的大块,挂到上一级 Order 的链表中。
这里提到的链表是第三章第六节引入的侵入式链表 linked_list,其特点是:链表的节点直接嵌入到空闲内存块内部。
先来看 buddy 内存分配器的主体结构 Heap:
// buddy_system_allocator/src/lib.rs
#![no_std]
use core::cmp::{min, max};
use core::alloc::Layout;
use core::mem::size_of;
use core::ptr::NonNull;
pub struct Heap<const ORDER: usize> {
free_list: [linked_list::LinkedList; ORDER],
used: usize,
allocated: usize,
total: usize,
}
impl<const ORDER: usize> Heap<ORDER> {
pub const fn new() -> Self {
Heap {
free_list: [linked_list::LinkedList::new(); ORDER],
used: 0,
allocated: 0,
total: 0,
}
}
pub const fn empty() -> Self {
Self::new()
}
}
// buddy_allocator/Cargo.toml
[dependencies]
linked_list = { path = "../linked_list" }第 10 行:free_list 的类型是长度为 Order 的数组,数组元素的类型是侵入式链表 LinkedList。对应上图的设计结构。
// buddy_system_allocator/src/lib.rs
impl<const ORDER: usize> Heap<ORDER> {
pub unsafe fn add_to_heap(&mut self, mut start: usize, mut end: usize) {
start = (start + size_of::<usize>() - 1) & (!size_of::<usize>() + 1);
end &= !size_of::<usize>() + 1;
assert!(start <= end);
let mut total = 0;
let mut current_start = start;
while current_start + size_of::<usize>() <= end {
let lowbit = current_start & (!current_start + 1);
let size = min(lowbit, prev_power_of_two(end - current_start));
total += size;
self.free_list[size.trailing_zeros() as usize].push(current_start as *mut usize);
current_start += size;
}
self.total += total;
}
pub unsafe fn init(&mut self, start: usize, size: usize) {
self.add_to_heap(start, start + size);
}
}
pub(crate) fn prev_power_of_two(num: usize) -> usize {
1 << (usize::BITS as usize - num.leading_zeros() as usize - 1)
}第 3~18 行,初始化内存分配器的核心方法 add_to_heap,根据新增的内存段的大小找到合适的 Order,插入对应链表。
// buddy_system_allocator/src/lib.rs
impl<const ORDER: usize> Heap<ORDER> {
pub fn alloc(&mut self, layout: Layout) -> Result<NonNull<u8>, ()> {
let size = max(
layout.size().next_power_of_two(),
max(layout.align(), size_of::<usize>()),
);
let class = size.trailing_zeros() as usize;
for i in class..self.free_list.len() {
if !self.free_list[i].is_empty() {
for j in (class + 1..i + 1).rev() {
if let Some(block) = self.free_list[j].pop() {
unsafe {
self.free_list[j - 1]
.push((block as usize + (1 << (j - 1))) as *mut usize);
self.free_list[j - 1].push(block);
}
} else {
return Err(());
}
}
let result = NonNull::new(
self.free_list[class]
.pop()
.expect("current block should have free space now")
as *mut u8,
);
if let Some(result) = result {
self.used += layout.size();
self.allocated += size;
return Ok(result);
} else {
return Err(());
}
}
}
Err(())
}
pub fn dealloc(&mut self, ptr: NonNull<u8>, layout: Layout) {
let size = max(
layout.size().next_power_of_two(),
max(layout.align(), size_of::<usize>()),
);
let class = size.trailing_zeros() as usize;
unsafe {
self.free_list[class].push(ptr.as_ptr() as *mut usize);
let mut current_ptr = ptr.as_ptr() as usize;
let mut current_class = class;
while current_class < self.free_list.len() {
let buddy = current_ptr ^ (1 << current_class);
let mut flag = false;
for block in self.free_list[current_class].iter_mut() {
if block.value() as usize == buddy {
block.pop();
flag = true;
break;
}
}
if flag {
self.free_list[current_class].pop();
current_ptr = min(current_ptr, buddy);
current_class += 1;
self.free_list[current_class].push(current_ptr as *mut usize);
} else {
break;
}
}
}
self.used -= layout.size();
self.allocated -= size;
}
}第 9~37 行:当分配内存块时,逐级向上找到能满足分配的最小块,取出后不断平分下去,直至大小刚好大于申请目标的大小。此外,每次平分剩余的后半部分都挂到对应大小的链表上。
第 51~69 行:释放内存块时正好相反,先尝试与它的伙伴块进行合并,逐级向上尝试,直到不能合并为止,最后挂到对应 Order 链表上。
下面引入测试用例验证一下 buddy 内存分配器的功能:
// buddy_allocator/tests/test_heap.rs
use core::alloc::Layout;
use core::mem::size_of;
use buddy_allocator::Heap;
#[test]
fn test_empty_heap() {
let mut heap = Heap::<32>::new();
assert!(heap.alloc(Layout::from_size_align(1, 1).unwrap()).is_err());
}
#[test]
fn test_heap_add() {
let mut heap = Heap::<32>::new();
assert!(heap.alloc(Layout::from_size_align(1, 1).unwrap()).is_err());
let space: [usize; 100] = [0; 100];
unsafe {
heap.add_to_heap(space.as_ptr() as usize, space.as_ptr().add(100) as usize);
}
let addr = heap.alloc(Layout::from_size_align(1, 1).unwrap());
assert!(addr.is_ok());
}
#[test]
fn test_heap_oom() {
let mut heap = Heap::<32>::new();
let space: [usize; 100] = [0; 100];
unsafe {
heap.add_to_heap(space.as_ptr() as usize, space.as_ptr().add(100) as usize);
}
assert!(heap
.alloc(Layout::from_size_align(100 * size_of::<usize>(), 1).unwrap())
.is_err());
assert!(heap.alloc(Layout::from_size_align(1, 1).unwrap()).is_ok());
}
#[test]
fn test_heap_alloc_and_free() {
let mut heap = Heap::<32>::new();
assert!(heap.alloc(Layout::from_size_align(1, 1).unwrap()).is_err());
let space: [usize; 100] = [0; 100];
unsafe {
heap.add_to_heap(space.as_ptr() as usize, space.as_ptr().add(100) as usize);
}
for _ in 0..100 {
let addr = heap.alloc(Layout::from_size_align(1, 1).unwrap()).unwrap();
heap.dealloc(addr, Layout::from_size_align(1, 1).unwrap());
}
}执行 make test,测试通过!
第六节 集成字节内存分配器
现在 buddy 内存分配器也已经准备好,下面就是启用它成为正式的字节内存分配器,完全替换掉早期内存分配器的功能,内核从本节开始将获得完整的内存管理功能。
分两步实现 GlobalAllocator 对正式的字节内存分配器的支持。
第一步,封装上节实现的基于 buddy 算法的字节内存分配器:
// axalloc/src/buddy.rs
use core::ptr::NonNull;
use crate::{Layout, AllocResult, AllocError};
use buddy_allocator::Heap;
pub struct BuddyByteAllocator {
inner: Heap<32>,
}
impl BuddyByteAllocator {
pub const fn new() -> Self {
Self {
inner: Heap::<32>::new(),
}
}
}
impl BuddyByteAllocator {
pub fn init(&mut self, start: usize, size: usize) {
unsafe { self.inner.init(start, size) };
}
}
// axalloc/Cargo.toml
[dependencies]
buddy_allocator = { path = "../buddy_allocator" }第 7 行:简单封装上节实现的内存分配器,最大 Order 设置为 32。
第 17~19 行:初始化字节分配器,指定一段内存范围用于当前的字节分配功能。
实现最基本的基于字节分配/释放的方法:
// axalloc/src/buddy.rs
impl BuddyByteAllocator {
pub fn alloc_bytes(&mut self, layout: Layout) -> AllocResult<NonNull<u8>> {
self.inner.alloc(layout).map_err(|_| AllocError::NoMemory)
}
pub fn dealloc_bytes(&mut self, pos: NonNull<u8>, layout: Layout) {
self.inner.dealloc(pos, layout)
}
}简单调用内部分配器的对应功能。
第二步,扩展 GlobalAllocator 启用字节分配:
// axalloc/src/lib.rs
mod buddy;
use buddy::BuddyByteAllocator;
const MIN_HEAP_SIZE: usize = 0x8000; // 32 K
struct GlobalAllocator {
early_alloc: SpinRaw<EarlyAllocator>,
page_alloc: SpinRaw<BitmapPageAllocator>,
byte_alloc: SpinRaw<BuddyByteAllocator>,
finalized: BootOnceCell<bool>,
}
impl GlobalAllocator {
pub const fn new() -> Self {
Self {
early_alloc: SpinRaw::new(EarlyAllocator::uninit_new()),
page_alloc: SpinRaw::new(BitmapPageAllocator::new()),
byte_alloc: SpinRaw::new(BuddyByteAllocator::new()),
finalized: BootOnceCell::new(),
}
}
}第 9 和 18 行:引入和初始化字节分配器。
impl GlobalAllocator {
fn alloc_bytes(&self, layout: Layout) -> *mut u8 {
let ret = if self.finalized.is_init() {
self.byte_alloc.lock().alloc_bytes(layout)
} else {
self.early_alloc.lock().alloc_bytes(layout)
};
if let Ok(ptr) = ret {
ptr.as_ptr()
} else {
alloc::alloc::handle_alloc_error(layout)
}
}
fn dealloc_bytes(&self, ptr: *mut u8, layout: Layout) {
if self.finalized.is_init() {
self.byte_alloc.lock().dealloc_bytes(
NonNull::new(ptr).expect("dealloc null ptr"),
layout
)
} else {
self.early_alloc.lock().dealloc_bytes(
NonNull::new(ptr).expect("dealloc null ptr"),
layout
)
}
}
}第 2~14 行:GlobalAllocator 面向字节分配的接口,根据 finalized 决定调用早期还是正式的内存分配器。
第 15~17 行:相应的,GlobalAllocator 面向字节释放的接口,同样基于 finalized 区分处于那个阶段。
下面在 GlobalAllocator 中启用字节分配:
实际上 GlobalAllocator 的两个子分配器 - 字节分配与页分配,它们之间并非并列关系,而是存在一个层次间关联。
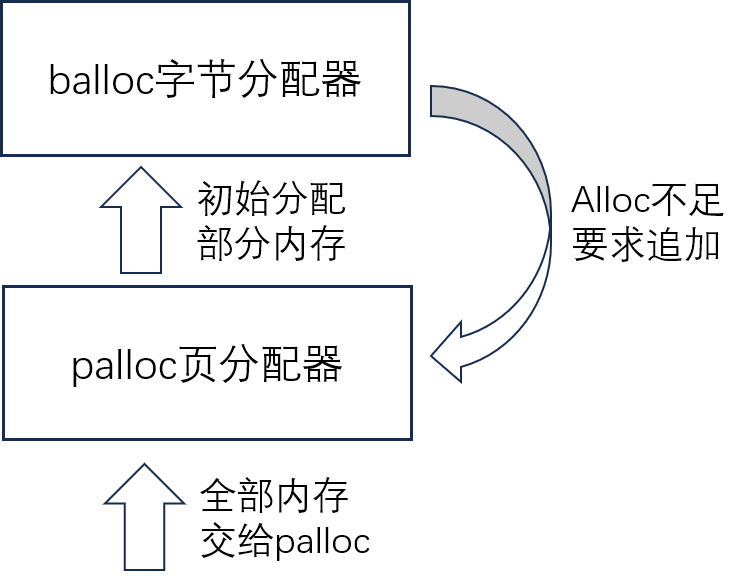
- 系统的全部内存由页分配器负责管理,它提供一组页作为字节分配器的初始内存。
- 当字节分配器的现有内存不足以满足请求时,它会向页分配器要求追加更多的内存页再进行分配,直至页分配器无法满足时才会真正失败。
先来实现第 1 条功能,扩展 final_init(...),之前只是处理了页分配,下面来启用字节分配。
// axalloc/src/lib.rs
impl GlobalAllocator {
pub fn final_init(&self, start: usize, size: usize) {
self.page_alloc.lock().init(start, size);
let layout = Layout::from_size_align(MIN_HEAP_SIZE, PAGE_SIZE).unwrap();
let heap_ptr = self.alloc_pages(layout) as usize;
self.byte_alloc.lock().init(heap_ptr, MIN_HEAP_SIZE);
self.finalized.init(true);
}
}第 5~7 行:从页分配器申请了一组页,用于初始化字节分配器。
验证一下当前实现的字节分配功能是否正常,在组件 axorigin 中申请一个长度为 4K 的长字节:
// axorigin/src/main.rs
pub fn main(_hartid: usize, _dtb: usize) {
... ...
try_alloc_pages();
try_alloc_long_string();
... ...
}
fn try_alloc_long_string() {
use core::alloc::Layout;
extern crate alloc;
const LENGTH: usize = 0x1000;
let layout = Layout::from_size_align(LENGTH, 1).unwrap();
let p = unsafe { alloc::alloc::alloc(layout) };
println!("Allocate long string: [{:?}].", p);
unsafe { alloc::alloc::dealloc(p, layout) };
println!("Release long string ok!");
}执行 make run,显示结果:
ArceOS is starting ...
Now: 0.111465 Hello, ArceOS![from String] Allocate pages: [0xffffffc08026c000]. Release pages ok! Allocate long string: [0xffffffc0801f9000]. Release long string ok! Elapsed: 0.008842
测试正常!
继续实现第 2 条 - 当字节分配内存不足时,从页分配器中申请追加更多页面扩展可分配的范围,除非页分配器的内存也耗尽才会导致失败。主要是对 GlobalAllocator 的字节分配函数进行简单的改造:
// axalloc/src/lib.rs
use log::info;
impl GlobalAllocator {
fn alloc_bytes(&self, layout: Layout) -> *mut u8 {
if !self.finalized.is_init() {
return self.early_alloc.lock().alloc_bytes(layout).unwrap().as_ptr();
}
loop {
let mut balloc = self.byte_alloc.lock();
if let Ok(ptr) = balloc.alloc_bytes(layout) {
return ptr.as_ptr();
} else {
let old_size = balloc.total_bytes();
let expand_size = old_size
.max(layout.size())
.next_power_of_two()
.max(PAGE_SIZE);
let layout = Layout::from_size_align(expand_size, PAGE_SIZE).unwrap();
let heap_ptr = self.alloc_pages(layout) as usize;
info!(
"expand heap memory: [{:#x}, {:#x})",
heap_ptr,
heap_ptr + expand_size
);
let _ = balloc.add_memory(heap_ptr, expand_size);
}
}
}
}第 12 行:先尝试从现有的内存范围内申请内存,如果内存不足,将会触发第 15~27 行的流程。
第 15~27 行:从页分配器中申请追加更多的页面用作字节分配。从第 15 到 19 行可以看出,每次请求量都是翻倍,但至少要申请一页。
上面实现涉及两个 buddy 分配器没有实现的功能,补上:
// axalloc/src/buddy.rs
impl BuddyByteAllocator {
pub fn add_memory(&mut self, start: usize, size: usize) -> AllocResult {
unsafe { self.inner.add_to_heap(start, start + size) };
Ok(())
}
pub fn total_bytes(&self) -> usize {
self.inner.stats_total_bytes()
}
}
// buddy_allocator/src/lib.rs
impl<const ORDER: usize> Heap<ORDER> {
pub fn stats_total_bytes(&self) -> usize {
self.total
}
}
// axalloc/Cargo.toml
[dependencies]
log = "0.4"下面来测试一下,在 axorigin 中尝试申请大于 1M 的内存,完整验证新的字节内存分配功能。
// axorigin/src/main.rs
const LENGTH: usize = 0x200000;只需要修改一行,把长度从 0x1000 扩大为 0x200000,再次执行 make run,观察结果:
ArceOS is starting ...
Now: 0.111744 Hello, ArceOS![from String] Allocate pages: [0xffffffc08026d000]. Release pages ok! Allocate long string: [0xffffffc080600000]. Release long string ok! Elapsed: 0.011159
申请大于 1M 内存(即超过 early 分配器的最大分配能力),仍然执行成功!
本章总结
本章,我们重新建立了地址空间映射,内核可以更加精确有效的管理内存和设备资源。我们还实现并启用了正式的动态内存分配器,包括一个基于 bitmap 算法的页分配器,一个基于 buddy 算法的字节分配器,然后建立了字节分配器与页分配器之间的依存关系。现在内存分配器可以基于平台提供的全部物理内存,进行页与字节的分配。内存管理子系统是整个内核运行的基石,后面我将基于它提供的基础服务,继续初始化任务管理、设备管理等子系统和功能。
第五章 多任务1 - 从串行到并发
从内核启动到目前为止,我们的内核一直在单任务的环境下运行,所有的执行步骤都是串行。从本章开始,我们将逐步支持多任务,这将引入更多的复杂性,我们也将面临更多的挑战。本章的目标是,引入基本概念包括任务、上下文切换、调度队列等,建立起多任务调度框架,并支持最简单的调度策略 - 先入先出的协作式调度。
第一节 基本概念 - 任务与调度
在现代操作系统中,多任务支持是基本功能。对我们的内核来说,所支撑的应用可以开启多任务,同时执行多条相对独立的逻辑流程;内核内部同样可以开启多任务,并发完成一些维护性的工作。无论在哪一个层面,合理的多任务调度都可以带来整体效率上的提升。
在多任务方面,任务与调度是两个核心的概念。
任务是被调度的对象,它具有独立的工作逻辑。
调度是资源不足时,协调每个请求对资源使用的方法。通常,每个任务都在尽力争取获得更多的计算资源 - 其实就是 CPU 时间,但是 CPU 无论从数量还是算力常常是处于相对不足的状态的,这就需要协调各个任务之间对有限 CPU 资源的分配。协调的好,系统整体效率有保证;协调的不好,系统效率下降甚至卡死。
在 ArceOS 的语境下,任务等价于线程。也就是说,每个任务拥有独立的执行流和独立的栈,但是它们没有独立的地址空间,而是共享唯一的内核地址空间。相应的对于调度,我们也需要更多的去参考线程调度方面的历史经验。
任务的核心构成要素包括:执行流、栈、环境上下文和状态。先来说状态,有四个基本的调度状态:
调度过程中,需要随时跟踪和更新任务的状态,作为对任务有效管理的基础。
下面以一个典型任务的生命周期为例,说明任务各个构成要素分别的职责作用:

上图是一个典型任务在整个生命周期过程中,将会(可能会)遇到的几种情况。
- 任务首次被创建时,status 默认是 Ready 状态,entry 为任务执行的入口,创建单独的由 kstack 指向的栈,还需要预留一块空间作为任务上下文 context,用于在任务被调度出去时,保存该任务的运行环境,以便在调度回来时恢复现场。
- 任务被调度运行,status 改为 Running 状态,有一个特殊的指针 CurrentTask 指向它,表示它就是当前正在被执行的任务。任务一旦启动之后,entry 就不再有用,寄存器 pc 始终指向 CPU 当前正在执行的指令,寄存器 sp 则指向 kstack 栈的栈顶位置。
- 任务在运行过程中可能随时被调度出去,使得 CPU 可以执行其它任务。调度出去的原因有两种:一是它必须等待某种资源可用,此时任务被设置为 Blocked 状态,让出执行权;二是它主动(调用 yield)或被动(时间片耗尽)让出执行权。无论何种原因,当前任务的上下文必须被首先被保存,即保护现场,等到该任务再次被调度时,把上下文再恢复出来,让任务从上次的断点处继续运行。后面我们将会看到,所谓任务的上下文,就是一组维持任务运行状态的必要的寄存器。
- 任务在运行中,还会遇到另外一种涉及运行环境保存与恢复的情况,即触发异常或遇到外部中断时。此时系统应该挂起当前任务,转而去执行异常/中断的例程,处理完成后再回到任务断点处恢复执行。这期间内核处于一个特殊的运行上下文中,我们称为异常中断上下文,它会叠加到当前任务的任务上下文之上。具体来说,当前任务的一组寄存器状态会作为 TrapFrame 被保存在任务的栈上。
- 任务运行完成后,它的某些资源不能被自己回收,所以内核安排了一个内部任务 GcTask,专门负责进行此项工作。
XXX
根据上面的说明,我们先把任务相关的结构定义出来,首先是 Task 和 CurrentTask 定义在 axtask/src/task.rs:
#[repr(u8)]
#[derive(Debug, Clone, Copy, Eq, PartialEq)]
pub(crate) enum TaskState {
Running = 1,
Ready = 2,
Blocked = 3,
Exited = 4,
}
struct TaskStack {
ptr: NonNull<u8>,
layout: Layout,
}
pub struct Task {
entry: Option<*mut dyn FnOnce()>,
state: AtomicU8,
kstack: Option<TaskStack>,
ctx: UnsafeCell<TaskContext>,
}
unsafe impl Send for Task {}
unsafe impl Sync for Task {}
pub struct CurrentTask(ManuallyDrop<AxTaskRef>);
pub fn current() -> CurrentTask {
CurrentTask::get()
}而 TaskContext 因为与体系结构相关,定义在 axhal/src/riscv64/context.rs 中:
#[repr(C)]
#[derive(Debug, Default)]
pub struct TaskContext {
pub ra: usize, // return address (x1)
pub sp: usize, // stack pointer (x2)
pub s0: usize, // x8-x9
pub s1: usize,
pub s2: usize, // x18-x27
pub s3: usize,
pub s4: usize,
pub s5: usize,
pub s6: usize,
pub s7: usize,
pub s8: usize,
pub s9: usize,
pub s10: usize,
pub s11: usize,
}XXX
第二节 初始任务 - MainTask
内核从启动开始的主执行流程,将来也会作为一个任务参与多任务的调度,我们称它为 MainTask。这个初始任务有它的特殊性,无论是初始化还是调度方面,都需要特殊处理。后续我们将要创建的那些任务,都是 MainTask 的分支和子任务,需要受到它的管理。这一节我们先来建立起 MainTask 的运行框架,为后面创建更多的任务做一个准备。
完整的 MainTask 的运行过程如下,主要关注三个阶段:封装 MainTask、尝试调度执行 yield 和 exit 退出系统。

封装 MainTask
内核启动之后,以单线程方式执行一系列的初始化步骤,直至初始化多任务这一步。此时需要把当前这个执行流程本身也封装为一个任务 MainTask,以便将来与其它任务一起接受调度。MainTask 的特殊之处在于:首先它当前就正处于运行状态,所以初始 status 就是 Running 而非 Ready,并且它在初始化后直接就是 CurrentTask;此外,它的 entry 无意义置空,kstack 也不必创建,因为已经存在,就是内核栈。封装构建 MainTask 的代码在 axtask/src/run_queue.rs 的 init(...) 中:
pub(crate) fn init() {
let main_task = Task::new_init("main".into());
main_task.set_state(TaskState::Running);
unsafe { CurrentTask::init_current(main_task) }
}构造 main_task 实例后,直接设置 state 是 Running,然后让 CurrentTask 指向该任务。
看一下 MainTask 的初始化方法:
impl Task {
pub(crate) fn new_init(name: String) -> AxTaskRef {
let mut t = Self::new_common(TaskId::new(), name);
t.is_init = true;
Arc::new(t)
}
fn new_common(id: TaskId, name: String) -> Self {
Self {
name,
entry: None,
state: AtomicU8::new(TaskState::Ready as u8),
kstack: None,
ctx: UnsafeCell::new(TaskContext::new()),
}
}
#[inline]
pub(crate) fn set_state(&self, state: TaskState) {
self.state.store(state as u8, Ordering::Release)
}
}CurrentTask::init_current 用于指明当前任务,实际是调用 axhal 的实现【记录在 tp 中】:
// axtask/src/task.rs
impl CurrentTask {
pub(crate) unsafe fn init_current(init_task: AxTaskRef) {
let ptr = Arc::into_raw(init_task);
axhal::cpu::set_current_task_ptr(ptr);
}
pub(crate) fn try_get() -> Option<Self> {
let ptr: *const Task = axhal::cpu::current_task_ptr();
if !ptr.is_null() {
Some(Self(unsafe { ManuallyDrop::new(AxTaskRef::from_raw(ptr)) }))
} else {
None
}
}
pub(crate) fn get() -> Self {
Self::try_get().expect("current task is uninitialized")
}
}
pub fn current() -> CurrentTask {
CurrentTask::get()
}
// axhal/src/riscv64/cpu.rs
static mut CURRENT_TASK_PTR: usize = 0;
#[inline]
pub fn current_task_ptr<T>() -> *const T {
unsafe { CURRENT_TASK_PTR as _ }
}
#[inline]
pub unsafe fn set_current_task_ptr<T>(ptr: *const T) {
CURRENT_TASK_PTR = ptr as usize
}有两个系列的函数,由 axtask 和 axhal 共同实现。一组是全局函数 current() 及其支撑,用于返回当前正在执行的任务指针;另一组是初始化或设置当前任务的函数。它们在后面的调度中,都会起到重要作用。
下面来考虑一下调度的问题,除了 Task 之外,调度还涉及两个数据结构,当前任务指针 CurrentTask 和任务运行队列 run_queue。

如图,我们内核中任务的调度,常称为 resched,主要要解决的问题就是:确定谁是下一个执行任务,这是通过在 CurrentTask 和 run_queue 之间交换任务来实现。
通过前面提到的 current() 函数可以获得 CurrentTask,它指向当前任务。在调度时,必须完整的执行如下两步:
第一步 Put - 把当前任务放回到运行队列 run_queue 中。
第二步 Get - 从运行队列 run_queue 中取出一个任务作为当前任务。
注意:一定是先把当前任务放回运行队列,然后再从队列中选出下一个任务。这意味着,当前任务也会与运行队列中的其它任务一起平等的参与竞争,基于调度策略选出下一个,所以选择结果仍有可能是它。
完成上述两步之后,可能出现 3 种结果:
- 当前任务变成了另外一个。这是最常见的情况,说明调度生效了,CPU 开始执行目前更有资格或更紧迫的任务。至于谁更有资格或更紧迫取决于调度的策略。
- 当前任务还是调度前的那个任务,相当于调度没有生效。这可能是因为 run_queue 是空的,也有可能在所有待命的任务中,原任务依然是最有资格执行的那个。
- 上面第二步 Get 取不到下一个可执行的任务。对于此情况,内核中预设一个名为 IDLE 的特殊的内部任务,充当下一个任务,它名副其实的什么都不做,一旦有其它有效的任务可以运行了,它就会立即让出。本节不涉及它,我们将在本章的最后,说明它的实现。
由于我们目前只有一个任务 MainTask,如果触发调度,将出现上面第 2 种结果,即调度后仍然是 MainTask。
下面来实现 yield api 和背后的 resched 过程,首先是运行队列 run_queue 的实现:
pub(crate) static RUN_QUEUE: SpinNoIrq<AxRunQueue> = SpinNoIrq::new(AxRunQueue::new());
pub(crate) struct AxRunQueue {
ready_queue: VecDeque<Arc<Task>>,
}
impl AxRunQueue {
pub fn yield_current(&mut self) {
self.resched();
}
fn resched(&mut self) {
let prev = current();
if prev.is_running() {
prev.set_state(TaskState::Ready);
if !prev.is_idle() {
self.put_prev_task(prev.clone());
}
}
let next = self.pick_next_task().unwrap(); // FixMe: with IDLE_TASK.get().clone()
self.switch_to(prev, next);
}
fn switch_to(&mut self, prev_task: CurrentTask, next_task: AxTaskRef) {
next_task.set_preempt_pending(false);
next_task.set_state(TaskState::Running);
if prev_task.ptr_eq(&next_task) {
return;
}
todo!("Implement it in future!");
}
pub fn pick_next_task(&mut self) -> Option<Arc<Task>> {
self.ready_queue.pop_front()
}
pub fn put_prev_task(&mut self, prev: Arc<Task>, preempt: bool) {
self.ready_queue.push_back(prev)
}
}运行队列采取 VecDeque 的数据结构,可以方便的在两头进行 push/pop。
注意 yield_current,其实就是调用 resched(),实现逻辑已经在上面交代过了,最后是对前后两个任务执行 switch_to 切换。
关于 switch_to(...) 函数,这个是整个调度机制的核心,本节的实现是不完整的,但是那句 todo! 不会被执行到,因为目前我们只有一个任务 MainTask,是在同一个任务上切换,从上面那行 return 就返回了。下一节我们来完成这个 switch_to(...) 函数。
然后,把 yield 的功能通过 axstd 暴露给应用:
// axstd/src/thread.rs
pub fn yield_now() {
axtask::yield_now();
}
// axtask/src/lib.rs
pub fn yield_now() {
run_queue::RUN_QUEUE.lock().yield_current();
}
最后,我们为 MainTask 实现 exit:
// axtask/src/lib.rs
pub fn exit(exit_code: i32) -> ! {
run_queue::RUN_QUEUE.lock().exit_current(exit_code)
}
// axtask/src/run_queue.rs
impl AxRunQueue {
pub fn exit_current(&mut self, exit_code: i32) -> ! {
axhal::misc::terminate();
}
}对于 MainTask,任务退出就意味着系统退出。但是对于其它任务,则只是自己退出,并等待资源被回收。所以 exit_current(...) 的实现是不完整的,下一节我们再来完成它。
在 axruntime 中,初始化 axtask 组件,以支持多任务:
// axruntime/src/lib.rs
pub extern "C" fn rust_main(hartid: usize, dtb: usize) -> ! {
... ...
axtask::init_scheduler();
... ...
unsafe {
main();
}
axtask::exit(0);
}
pub fn init_scheduler() {
info!("Initialize scheduling...");
run_queue::init();
}现在来运行一下,从运行效果来看,与启用多任务之前没有区别,毕竟目前也只有一个任务;但是在形式上,我们已经完成了多任务框架的支持,为并发计算与按策略调度做好了准备。
下一节,我们将通过 spawn 这个 API 创建一个新的任务,完善调度机制,与初始任务形成真正的并发关系。
第三节 创建任务 - spawn
前面我们已经让内核的主线程成为第一个任务 MainTask;本节将在 MainTask 的基础上,创建一个应用级的任务。流程如下:

创建新任务 spawn
首先来实现 spawn 新任务的 API,扩展 axstd/thread,如下:
pub fn spawn<T, F>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T + 'static,
T: 'static,
{
Builder::new().spawn(f).expect("failed to spawn thread")
}
#[derive(Debug)]
pub struct Builder {
// A name for the thread-to-be, for identification in panic messages
name: Option<String>,
// The size of the stack for the spawned thread in bytes
stack_size: Option<usize>,
}
impl Builder {
pub const fn new() -> Builder {
Builder {
name: None,
stack_size: None,
}
}
pub fn spawn<F, T>(self, f: F) -> io::Result<JoinHandle<T>>
where
F: FnOnce() -> T + 'static,
F: 'static,
T: 'static,
{
unsafe { self.spawn_unchecked(f) }
}
unsafe fn spawn_unchecked<F, T>(self, f: F) -> Result<JoinHandle<T>>
where
F: FnOnce() -> T + 'static,
F: 'static,
T: 'static,
{
let name = self.name.unwrap_or_default();
let stack_size = self
.stack_size
.unwrap_or(axconfig::TASK_STACK_SIZE);
let my_packet = Arc::new(Packet {
result: UnsafeCell::new(None),
});
let their_packet = my_packet.clone();
let main = move || {
let ret = f();
unsafe { *their_packet.result.get() = Some(ret) };
drop(their_packet);
};
let inner = axtask::spawn_raw(main, name, stack_size);
let task = AxTaskHandle {
id: inner.id().as_u64(),
inner,
};
Ok(JoinHandle {
thread: Thread::from_id(task.id),
native: task,
packet: my_packet,
})
}
}API 这一层负责组织好三个参数,任务的入口、名称和栈大小,然后调用 axtask::spawn_raw(...) 进行实际的创建过程,最后以 JoinHandle 的形式返回任务的句柄和返回值 packet。
关键是 axtask::spawn_raw 的实现:
// axtask/src/lib.rs
pub fn spawn_raw<F>(f: F, name: String, stack_size: usize) -> AxTaskRef
where
F: FnOnce() + 'static,
{
let task = task::Task::new(f, name, stack_size);
run_queue::RUN_QUEUE.lock().add_task(task.clone());
task
}
// axtask/src/task.rs
impl Task {
pub(crate) fn new<F>(entry: F, name: String, stack_size: usize) -> AxTaskRef
where
F: FnOnce() + 'static,
{
let mut t = Self::new_common(TaskId::new(), name);
let kstack = TaskStack::alloc(align_up(stack_size, PAGE_SIZE));
t.entry = Some(Box::into_raw(Box::new(entry)));
t.ctx.get_mut().init(task_entry as usize, kstack.top());
t.kstack = Some(kstack);
Arc::new(t)
}
}
extern "C" fn task_entry() -> ! {
let task = current();
if let Some(entry) = task.entry {
unsafe { Box::from_raw(entry)() };
}
crate::exit(0);
}
// axtask/src/run_queue.rs
impl AxRunQueue {
pub fn add_task(&mut self, task: AxTaskRef) {
self.ready_queue.push_back(task);
}
}spawn_raw 包括两步,第一步是创建新任务,第二步则是简单的把它加到 run_queue 队列中等待调度。
关键是创建新任务这一步,与上一节 MainTask 的初始化不同,这次任务的 entry 是应用的计算逻辑的入口,同时需要创建一个自己的栈。然后注意上下文 ctx 的初始化,我们把任务的入口 task_entry 和新建栈的栈顶位置填充进去,这是下面调度到该任务时,任务能够从正确的位置执行应用逻辑的关键。
让出执行权 yield - 触发调度
下面就来看一下对新建任务首次调度的过程。
上一节我们已经建立了从 yield 和它背后 resched 的基本过程,但这次情况不同,运行队列 run_queue 中有了一个处于 Ready 状态的可调度任务,因此 switch_to 函数会发生一次真正的任务切换。
impl AxRunQueue {
fn switch_to(&mut self, prev_task: CurrentTask, next_task: AxTaskRef) {
next_task.set_preempt_pending(false);
next_task.set_state(TaskState::Running);
if prev_task.ptr_eq(&next_task) {
return;
}
// Just switch between two tasks.
unsafe {
let prev_ctx_ptr = prev_task.ctx_mut_ptr();
let next_ctx_ptr = next_task.ctx_mut_ptr();
CurrentTask::set_current(prev_task, next_task);
(*prev_ctx_ptr).switch_to(&*next_ctx_ptr);
}
}
}首先把下一个任务 - 即我们新建的应用任务,设置为 CurrentTask,然后在 axhal 中进行实际的上下文切换:
// axhal/src/riscv64/context.rs
impl TaskContext {
pub const fn new() -> Self {
unsafe { core::mem::MaybeUninit::zeroed().assume_init() }
}
pub fn init(&mut self, entry: usize, kstack_top: usize) {
self.sp = kstack_top;
self.ra = entry;
}
pub fn switch_to(&mut self, next_ctx: &Self) {
unsafe { context_switch(self, next_ctx) }
}
}
#[naked]
unsafe extern "C" fn context_switch(_current_task: &mut TaskContext, _next_task: &TaskContext) {
asm!("
// save old context (callee-saved registers)
sd ra, 0*8(a0)
sd sp, 1*8(a0)
sd s0, 2*8(a0)
sd s1, 3*8(a0)
sd s2, 4*8(a0)
sd s3, 5*8(a0)
sd s4, 6*8(a0)
sd s5, 7*8(a0)
sd s6, 8*8(a0)
sd s7, 9*8(a0)
sd s8, 10*8(a0)
sd s9, 11*8(a0)
sd s10, 12*8(a0)
sd s11, 13*8(a0)
// restore new context
ld s11, 13*8(a1)
ld s10, 12*8(a1)
ld s9, 11*8(a1)
ld s8, 10*8(a1)
ld s7, 9*8(a1)
ld s6, 8*8(a1)
ld s5, 7*8(a1)
ld s4, 6*8(a1)
ld s3, 5*8(a1)
ld s2, 4*8(a1)
ld s1, 3*8(a1)
ld s0, 2*8(a1)
ld sp, 1*8(a1)
ld ra, 0*8(a1)
ret",
options(noreturn),
)
}所谓上下文,就是能够保持任务状态的一组寄存器,从 context_switch 可以看出,寄存器组包括 ra、sp 和 s0~s11,处理过程就是把当前这组寄存器的值保存到上一个任务的 ctx 上下文中,然后用下一个任务的 ctx 上下文中保存的值来恢复对应的寄存器。
其中,ra 寄存器是函数返回后要执行的下一条指令地址,对它进行切换的效果:context_switch 返回后竟然不是返回到原任务执行流,而是返回到另一个执行流中;sp 寄存器指向栈,它保持了函数压栈的信息,所以在执行流切换的同时,栈也必须切换;s0~s11 是按照 RiscV 规范必须由被调用者负责保存的寄存器,因此一并放到上下文中随任务切换。context_switch 的执行效果如下:
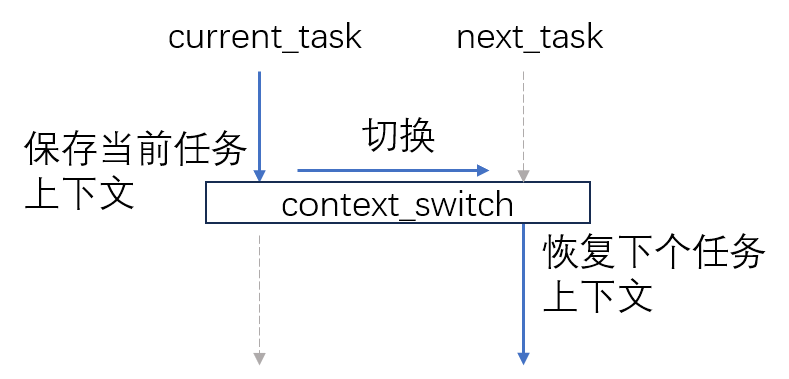
从图中可见,context_switch(...) 是一个非常特殊的函数,当前任务进入函数后被挂起;等函数返回时,继续执行的往往是另一个任务。
现在已经支持了任务调度的完整过程,内核从 MainTask 切换到了新建的 AppTask。AppTask 完成自己的工作之后,将会通过 exit 退出。我们在前面实现 task_entry(...) 时,最后一行就是 exit,所以应用任务不必显式调用它。下面来完善 exit 的实现。
应用任务退出 - exit
上一节实现了 exit 的框架,不过只是针对 MainTask 的情况。对于应用任务 AppTask,它退出时不会导致系统退出,只是通知系统对其资源进行回收。因此我们需要对 exit 进行分支处理:
// axtask/src/run_queue.rs
impl AxRunQueue {
pub fn exit_current(&mut self, exit_code: i32) -> ! {
let curr = current();
if curr.is_init() {
axhal::misc::terminate();
} else {
curr.set_state(TaskState::Exited);
// Save exit code and notify kernel to reclaim itself.
self.resched(false);
}
unreachable!("task exited!");
}
}任务 Task 的成员 is_init 标记自己是否就是 MainTask。对于普通的 AppTask,先设置 Exited 状态,然后记录退出码和通知内核回收,最后触发一次 resched 调度,把执行权再切换出去,它的使命已经完成,就等着被回收了。中间那一步“记录退出码和通知内核回收”暂缺,我们到下一节再补充相关的机制。
主任务 MainTask 调用 join 等待 AppTask 退出
这一步与 AppTask 的 exit 退出相对应,下一节专门讨论。
先来验证一下我们目前的成果:
执行成功!
第四节 任务退出和等待任务退出
上节中我们遗留了关于任务退出与等待其它任务退出的问题,这个问题的复杂性在于:任务有两个角色,一方面任务一定会在某个时刻退出,另一方面某个任务可能在运行中阻塞等待另一个任务的退出。关系如下:

至于任务之间是如何形成这样一种相互等待关系的?回顾上一节开头的流程图,MainTask 对 AppTask 调用 join,建立等待关系,然后把自己状态设置为 Blocked,从运行队列 run_queue 转移到等待队列 wait_queue,然后触发重新调度让出执行权。直到 AppTask 退出时,MainTask 作为等待者被重新唤醒,继续执行。
为实现上述功能,我们需要为 Task 增加一个等待者列表 waiting list,记录那些等待它退出的其它 Task。修改 Task 结构:
pub struct Task {
... ...
wait_for_exit: WaitQueue,
exit_code: AtomicI32,
... ...
}
impl Task {
pub(crate) fn notify_exit(&self, exit_code: i32, rq: &mut AxRunQueue) {
self.exit_code.store(exit_code, Ordering::Release);
self.wait_for_exit.notify_all_locked(rq);
}
pub fn join(&self) -> Option<i32> {
self.wait_for_exit.wait_until(|| self.state() == TaskState::Exited);
Some(self.exit_code.load(Ordering::Acquire))
}
}结构 Task 中增加 wait_for_exit 等待列表和退出码 exit_code。一方面实现 join 方法,挂起当前以等待目标任务的退出。相应的,实现 notify_exit 这个方法,用于记录退出码并通知所有等待者。
数据结构 WaitQueue 是类似于 AxRunQueue 的一个特殊队列,用于实现任务的等待与唤醒。
// axtask/src/wait_queue.rs
pub struct WaitQueue {
queue: SpinRaw<VecDeque<AxTaskRef>>, // we already disabled IRQs when lock the `RUN_QUEUE`
}
impl WaitQueue {
pub const fn new() -> Self {
Self {
queue: SpinRaw::new(VecDeque::new()),
}
}
pub fn wait_until<F>(&self, condition: F)
where
F: Fn() -> bool,
{
loop {
let mut rq = RUN_QUEUE.lock();
if condition() {
break;
}
rq.block_current(|task| {
self.queue.lock().push_back(task);
});
}
}
pub(crate) fn notify_all_locked(&self, rq: &mut AxRunQueue) {
while let Some(task) = self.queue.lock().pop_front() {
rq.unblock_task(task);
}
}
}
// axtask/src/run_queue.rs
impl AxRunQueue {
pub fn unblock_task(&mut self, task: AxTaskRef) {
if task.is_blocked() {
task.set_state(TaskState::Ready);
self.add_task(task);
}
}
pub fn block_current<F>(&mut self, wait_queue_push: F)
where
F: FnOnce(AxTaskRef),
{
let curr = current();
curr.set_state(TaskState::Blocked);
wait_queue_push(curr.clone());
self.resched(false);
}
}从上面的实现可以看出,当前任务 CurrentTask 调用 join,进而通过 WaitQueue::wait_until 进入等待队列中阻塞等待;直到所等待的任务退出,被从等待队列中唤醒,再回到运行队列中准备被调度,这步最后是通过AxRunQueue::unblock_task(...) 实现的。
最后来给出 exit 的完整功能,接上节对 exit_current 的实现:
// axtask/src/run_queue.rs
impl AxRunQueue {
pub fn exit_current(&mut self, exit_code: i32) -> ! {
let curr = current();
if curr.is_init() {
axhal::misc::terminate();
} else {
curr.set_state(TaskState::Exited);
// Save exit code and notify kernel to reclaim itself.
// [Begin]
curr.notify_exit(exit_code, self);
// [End]
self.resched(false);
}
unreachable!("task exited!");
}
}只是新增 [Begin]...[End] 中间的一行,任务调用 notify_exit 通知所有等待者一个消息 - “它正在退出”。
测试一下退出与等待功能,测试通过!
第五节 系统任务 - Gc 和 Idle 任务
上一节看到,对于任意一个应用任务,可以有若干个任务阻塞等待它的退出。实际上,更确切的说,对于任意一个应用任务,至少有一个任务在等待它退出。这个就是 Gc 任务,它负责回收已经退出的任务的资源。任务的处理逻辑:
fn gc_entry() {
loop {
let n = EXITED_TASKS.lock().len();
for _ in 0..n {
let task = EXITED_TASKS.lock().pop_front();
if let Some(task) = task {
if Arc::strong_count(&task) == 1 {
drop(task);
} else {
EXITED_TASKS.lock().push_back(task);
}
}
}
WAIT_FOR_EXIT.wait();
}
}另外,还有一个特殊的系统任务 Idle,当没有任何其它任务可以调度时,Idle 将临时充当 CPU 当前任务:
pub fn run_idle() -> ! {
loop {
yield_now();
}
}可以看到,它在不断尝试让出执行权。
这两个任务与主任务 MainTask 一起,都是在 run_queue 的 init 方法中被初始化建立的:
// axtask/src/run_queue.rs
pub(crate) fn init() {
const IDLE_TASK_STACK_SIZE: usize = 4096;
let idle_task = Task::new(|| run_idle(), "idle".into(), IDLE_TASK_STACK_SIZE);
IDLE_TASK.init(idle_task.clone());
let gc_task = Task::new(gc_entry, "gc".into(), axconfig::TASK_STACK_SIZE);
RUN_QUEUE.lock().add_task(gc_task);
let main_task = Task::new_init("main".into());
main_task.set_state(TaskState::Running);
unsafe { CurrentTask::init_current(main_task) }
}此外,为 Idle 任务的使用,在 resched(...) 方法中打个补丁:
impl AxRunQueue {
fn resched(&mut self, preempt: bool) {
... ....
let next = self.pick_next_task().unwrap_or_else(|| IDLE_TASK.get().clone());
self.switch_to(prev, next);
}
}注意:调用 pick_next_task 那一行,当找不到可以运行的下个任务时,就调度Idle这个任务。
至此,多任务支持的基本框架已经建立,打开 debug 日志测试一下,执行 make run LOG=debug 跟踪各个任务的运行日志,如下。
测试成功!
本章总结
本章,我们重新建立了地址空间映射,内核可以更加精确有效的管理内存和设备资源。我们还实现并启用了正式的动态内存分配器,包括一个基于 bitmap 算法的页分配器,一个基于 buddy 算法的字节分配器,然后建立了字节分配器与页分配器之间的依存关系。现在内存分配器可以基于平台提供的全部物理内存,进行页与字节的分配。内存管理子系统是整个内核运行的基石,后面我将基于它提供的基础服务,继续初始化任务管理、设备管理等子系统和功能。
第六章 异常和中断 - 响应异常和外部事件
计算机系统在正常执行程序的过程中,常常会遇到各种异常情况。一种是与当前正在执行的操作相关联的,例如指令非法、访问的地址不存在或无权限等等,我们称之为异常;另外一种往往是由外部事件所引发的,例如时钟定期发出的信号,硬盘控制器发出的故障或操作完成通知等等,我们称之为中断。异常由于是与当前操作相关的,一定程度上是可预测、可协调的;中断则是完全随机,无法预测和协调的,除非彻底关闭。
异常与中断对于内核具有非常关键的意义,是实现很多功能的必要基础。我们之前并未特意处理异常,也没有启用中断,本章我们就来完成对它们的处理。
第一节 异常处理
按照 RiscV 规范,异常和中断被触发时,当前的执行流程被打断,跳转到异常向量表中相应的例程进行处理。其中,stvec 寄存器指向的是向量表的基地址,scause 寄存器记录的异常编号则作为例程入口的偏移,二者相加得到异常处理例程的最终地址。
本节中,我们将准备一个符合规范的异常向量表,在内核启动阶段设置到 stvec 寄存器,此后,就可以逐步扩展向量表中注册的例程,去支持各种异常。看一下异常向量表,它采用汇编方式定义:
// axhal/src/riscv64/trap.S
.macro SAVE_REGS
addi sp, sp, -{trapframe_size}
PUSH_GENERAL_REGS
csrr t0, sepc
csrr t1, sstatus
csrrw t2, sscratch, zero // save sscratch (sp) and zero it
sd t0, 31*8(sp) // tf.sepc
sd t1, 32*8(sp) // tf.sstatus
sd t2, 1*8(sp) // tf.regs.sp
.endm
.macro RESTORE_REGS
ld t0, 31*8(sp)
ld t1, 32*8(sp)
csrw sepc, t0
csrw sstatus, t1
POP_GENERAL_REGS
ld sp, 1*8(sp) // load sp from tf.regs.sp
.endm
.section .text
.balign 4
.global trap_vector_base
trap_vector_base:
SAVE_REGS
mv a0, sp
call riscv_trap_handler
RESTORE_REGS
sret异常向量表实际是在 riscv_trap_handler 中处理,但在真正处理异常的前后,分别需要保存和恢复原始的上下文,我们称之为异常上下文,以与上一章提到的任务上下文进行区别。
在内核中,存在多种相互独立的运行环境,每一种环境都抽象为一种上下文,内核需要在必要时进行切换。
在前面一章 - 多任务支持中,重点说明了任务上下文,用于任务间切换;本节的上下文对应异常处理的场景,称之为异常上下文。
关于两种上下文的示意图:

注意:异常上下文实际是基于当前任务的栈进行保存和恢复的。
然后看一下异常处理的具体逻辑:
#[no_mangle]
fn riscv_trap_handler(tf: &mut TrapFrame) {
let scause = scause::read();
match scause.cause() {
Trap::Exception(E::Breakpoint) => handle_breakpoint(&mut tf.sepc),
_ => {
panic!(
"Unhandled trap {:?} @ {:#x}:\n{:#x?}",
scause.cause(),
tf.sepc,
tf
);
}
}
}
fn handle_breakpoint(sepc: &mut usize) {
log::debug!("Exception(Breakpoint) @ {:#x} ", sepc);
*sepc += 2
}先处理 BreakPoint 异常作为一个示例,简单的输出触发指令的地址,然后地址加 2,跳到下一条指令。以后可以仿照该异常,扩展异常处理的范围。
最后,设置异常上下文向量表:
// axhal/src/riscv64.rs
unsafe extern "C" fn rust_entry(hartid: usize, dtb: usize) {
extern "C" {
fn trap_vector_base();
fn rust_main(hartid: usize, dtb: usize);
}
trap::set_trap_vector_base(trap_vector_base as usize);
rust_main(hartid, dtb);
}测试异常机制,在 axorigin 中通过 ebreak 指令触发,make run LOG=debug 查看日志。验证成功。
第二节 自旋锁与中断
在真正开启和处理中断之前,这一节先来升级一下我们的自旋锁。
到目前为止,内核始终在单 CPU 上运行,我们也没有启用中断,这就意味着:我们的程序中不存在并发,那么就没有互斥的问题,自然也不需要锁。在第一章中,我们虽然实现了一个自旋锁,但那只是形式上的,是为了适应 Rust 编码规则而设立的一个空实现。
现在一旦启用中断,就会引起两种新的可能性:
- 当正常执行程序时,会随时被外部的中断而打断运行,然后就会去执行响应中断的例程。中断是随机不可预测的,这样有可能会把原本处于临界区中的一组操作打断,破坏它们的原子性、事务性。
- 虽然已经支持多任务并发,但这种并发是协作式的,即只有一个任务主动让出执行权时,另一个任务才能执行。因此,调度时机是可以协调的,完全可以避免打破临界区。但是下一步我们将基于时钟中断支持抢占式的并发,即任务调度可能随时发生,或许当前任务正好处于临界区中。
为了杜绝上述两种可能性,我们需要重构新的自旋锁。根据上面的分析,其实我们只要在锁期间,关闭中断即可。
定义自旋锁 SpinNoIrq 和对应的 guard 变量:
pub struct SpinNoIrq<T> {
data: UnsafeCell<T>,
}
pub struct SpinNoIrqGuard<T> {
irq_state: usize,
data: *mut T,
}
unsafe impl<T> Sync for SpinNoIrq<T> {}
unsafe impl<T> Send for SpinNoIrq<T> {}
impl<T> SpinNoIrq<T> {
#[inline(always)]
pub const fn new(data: T) -> Self {
Self {
data: UnsafeCell::new(data),
}
}
}加锁时,关中断和抢占:
impl<T> SpinNoIrq<T> {
#[inline(always)]
pub fn lock(&self) -> SpinNoIrqGuard<T> {
let irq_state = NoPreemptIrqSave::acquire();
SpinNoIrqGuard {
irq_state,
data: unsafe { &mut *self.data.get() },
}
}
}析构时,恢复中断和抢占状态:
impl<T> Drop for SpinNoIrqGuard<T> {
#[inline(always)]
fn drop(&mut self) {
NoPreemptIrqSave::release(self.irq_state);
}
}测试一下自旋锁的功能。测试成功!
第三节 时钟中断
内核在中断处理方面,与异常处理有着许多重合的部分,这主要体现在向量表机制上。这一节首先来扩展异常中断向量表,让内核具备处理中断的能力,然后实现对全局和具体中断的启用和关闭。让我们先从时钟中断入手。
扩展异常中断向量表的具体处理逻辑:
// axhal/src/riscv64/trap.rs
#[no_mangle]
fn riscv_trap_handler(tf: &mut TrapFrame) {
let scause = scause::read();
match scause.cause() {
... ...
Trap::Interrupt(_) => handle_irq_extern(scause.bits()),
... ...
}
}
/// Call the external IRQ handler.
#[allow(dead_code)]
pub(crate) fn handle_irq_extern(irq_num: usize) {
call_interface!(TrapHandler::handle_irq, irq_num);
}这里用到了 crate_interface,具体的 TrapHandler::handle_irq 实现在 axruntime 中:
// axruntime/src/trap.rs
#[cfg(all(target_os = "none", not(test)))]
struct TrapHandlerImpl;
#[cfg(all(target_os = "none", not(test)))]
#[crate_interface::impl_interface]
impl axhal::trap::TrapHandler for TrapHandlerImpl {
fn handle_irq(irq_num: usize) {
axhal::irq::dispatch_irq(irq_num);
}
}
// axhal/src/riscv64/irq.rs
static TIMER_HANDLER: BootOnceCell<IrqHandler> = unsafe {
BootOnceCell::new()
};
pub fn dispatch_irq(scause: usize) {
match scause {
S_TIMER => {
log::trace!("IRQ: timer");
TIMER_HANDLER.get()();
},
_ => panic!("invalid trap cause: {:#x}", scause),
}
}
pub fn register_handler(scause: usize, handler: IrqHandler) -> bool {
match scause {
S_TIMER => {
if !TIMER_HANDLER.is_init() {
TIMER_HANDLER.init(handler);
true
} else {
false
}
},
_ => panic!("invalid trap cause: {:#x}", scause),
}
}中断处理同样基于中断的编号 scause 来确定具体的例程,就是上面的 dispatch_irq(scause),看到它会再调用TIMER_HANDLER 这个代表时钟处理例程的句柄。
内核在 axruntime 启动过程中会初始化中断 irq 的设施,并注册时钟处理的例程:
#[no_mangle]
#[cfg(all(target_os = "none", not(test)))]
pub extern "C" fn rust_main(hartid: usize, dtb: usize) -> ! {
... ...
axtask::init_scheduler();
info!("Initialize interrupt handlers...");
#[cfg(all(target_os = "none", not(test)))]
init_interrupt();
#[cfg(not(test))]
unsafe {
main();
}
... ...
}
#[cfg(all(target_os = "none", not(test)))]
fn init_interrupt() {
use axhal::irq::TIMER_IRQ_NUM;
// Setup timer interrupt handler
const PERIODIC_INTERVAL_NANOS: u64 =
axhal::time::NANOS_PER_SEC / axconfig::TICKS_PER_SEC as u64;
static mut NEXT_DEADLINE: u64 = 0;
fn update_timer() {
let now_ns = axhal::time::current_time_nanos();
// Safety: we have disabled preemption in IRQ handler.
let mut deadline = unsafe { NEXT_DEADLINE };
if now_ns >= deadline {
deadline = now_ns + PERIODIC_INTERVAL_NANOS;
}
unsafe { NEXT_DEADLINE = deadline + PERIODIC_INTERVAL_NANOS };
trace!("now {} deadline {}", now_ns, deadline);
axhal::time::set_oneshot_timer(deadline);
}
axhal::irq::register_handler(TIMER_IRQ_NUM, || {
update_timer();
debug!("On timer tick!");
});
// Enable IRQs before starting app
axhal::irq::enable_irqs();
}注册了一个时钟中断的例程:设置一个 1 秒后触发的定时器,每次触发都会重置定时器,让其下个 1 秒后再次触发,由此形成一个周期定时器。其中,设置定时器通过 axhal::time 模块实现:
// axhal/src/riscv64/time.rs
const TIMER_FREQUENCY: u64 = 10_000_000; // 10MHz
pub const NANOS_PER_SEC: u64 = 1_000_000_000;
const NANOS_PER_TICK: u64 = NANOS_PER_SEC / TIMER_FREQUENCY;
#[inline]
pub fn current_ticks() -> u64 {
time::read() as u64
}
#[inline]
pub const fn ticks_to_nanos(ticks: u64) -> u64 {
ticks * NANOS_PER_TICK
}
#[inline]
pub fn current_time_nanos() -> u64 {
ticks_to_nanos(current_ticks())
}
pub fn set_oneshot_timer(deadline_ns: u64) {
sbi_rt::set_timer(nanos_to_ticks(deadline_ns));
}OpenSBI 本身已经封装了对定时器处理的功能,所以函数 set_oneshot_timer 只需要调用 SBI 的 ecall 即可设置定时器。
最后需要注意:在 init_interrupt 的最后,需要开启全局中断。
// axhal/src/riscv64/irq.rs
#[inline]
pub fn enable_irqs() {
unsafe { sstatus::set_sie() }
}测试一下 make run LOG=trace,从跟踪日志中可以看到,定时器以 1 秒为周期进行调度,测试通过!
本章总结
XX。
第七章 多任务2 - 从协作式到抢占式
第五章中,内核建立了最基本的任务调度机制,任务可以在运行过程中选择主动挂起,由调度机制把执行权转移给其它任务。也就是说,调度是由任务自愿和主动发起的,所有任务通过这种友好协作,共同保证系统整体能够有效的运行下去,当时的调度机制称为协作式。但是现实情况并不总是那么理想,任务本身逻辑的设计可能存在这样那样的缺陷,任务运行中可能遭遇各种意外而行为异常,又或者任务自己认为自身很重要,需要占用更多的计算资源,但从系统整体来看,情况并非如此。从现实经验来看,由任务自己来决定调度的问题往往是不适合的,这样的调度缺乏全局视野,也缺乏最基本的运行保障,因此协作式调度的适应场景范围是非常窄的。
本章,我们将在第五章调度框架的基础上,为内核引入抢占式调度机制。抢占式是以系统为主进行调度,任务配合完成的调度方法,在适当的条件下,当前任务的执行权会被剥夺,由系统转给当前更应该获得运行机会的任务,由此保证整个系统的正常运行能力。
第一节 任务调度中的抢占
抢占是操作系统调度方面的一个基本概念,通常是指,高优先级的任务可以抢占正在运行的低优先级任务的执行权。但是在各种操作系统设计的具体实践上,它们的具体策略、具体设计与实现方式存在差异。这一节,先来澄清 ArceOS 中,任务抢占采取的具体策略与方式。这个抢占机制有以下几个特点:
- 抢占是有条件的,并且包括内部条件和外部条件,二者同时具备时,才能触发抢占。内部条件指的是,在任务内部维护的某种状态达到条件,例如本次运行的时间片配额耗尽;外部条件指的是,内核可以在某些阶段,暂时关闭抢占,比如,下步我们的自旋锁就需要在加锁期间关闭抢占,以保证锁范围的原子性。由此可见,这个抢占是兼顾了任务自身状况的,一个正在运行的任务即使是低优先级,在达到内部条件之前,也不会被其它任务抢占。这与典型的硬实时操作系统的抢占就有着明显的区别。
- 抢占是边沿触发。在内部条件符合的前提下,外部状态从禁止抢占到启用抢占的那个变迁点,会触发一次抢占式重调度 resched。
内部条件涉及任务结构的升级和具体策略,这里我们采取一个最简单的调度策略 - Round-Robin:为每个任务分配相同数量的时间片配额,当前任务耗尽本次配额后可以被抢占,它被追加到运行队列的末尾,以此类推,形成一个环形的调度序列,每个任务都能获得近似相等的计算资源。先来看一下任务的数据结构:
// axtask/src/task.rs
pub struct Task {
... ...
need_resched: AtomicBool,
time_slice: AtomicIsize,
}
impl Task {
const MAX_TIME_SLICE: isize = 5;
fn new_common(id: TaskId, name: String) -> Self {
Self {
... ...
need_resched: AtomicBool::new(false),
time_slice: AtomicIsize::new(Self::MAX_TIME_SLICE),
}
}
pub fn reset_time_slice(&self) {
self.time_slice.store(Self::MAX_TIME_SLICE, Ordering::Release);
}
pub fn task_tick(&self) -> bool {
let old_slice = self.time_slice.fetch_sub(1, Ordering::Release);
old_slice <= 1
}
pub(crate) fn set_preempt_pending(&self, pending: bool) {
self.need_resched.store(pending, Ordering::Release)
}
}在任务 Task 中增加一个 time_slice 成员用于记录时间片的消耗情况,初始化为 MAX_TIME_SLICE。实现一个关键的方法 task_tick 用于维护任务的内部条件:每次时钟中断时,将自动调用此方法对时间片 time_slice 减 1,当减到 0 时,方法返回 true 表示任务内部状态满足了抢占条件。
第二节 抢占式调度框架
抢占式调度由时钟中断推动,现在就让调度与时钟中断关联起来,在注册响应函数时调用 axtask::on_timer_tick():
// axruntime/src/lib.rs
#[cfg(all(target_os = "none", not(test)))]
fn init_interrupt() {
... ...
axhal::irq::register_handler(TIMER_IRQ_NUM, || {
update_timer();
debug!("On timer tick!");
axtask::on_timer_tick();
});
// Enable IRQs before starting app
axhal::irq::enable_irqs();
}
// axtask/src/lib.rs
pub fn on_timer_tick() {
run_queue::RUN_QUEUE.lock().scheduler_timer_tick();
}
// axtask/src/run_queue.rs
impl AxRunQueue {
pub fn scheduler_timer_tick(&mut self) {
let curr = current();
if !curr.is_idle() && curr.task_tick() {
curr.set_preempt_pending(true);
}
}
}每次时钟中断时,最后会调用 scheduler_timer_tick(...),对于当前任务,如果 task_tick 返回 true,设置抢占标志表示任务本身已经具备了被抢占的条件。当然,这只是满足了内部条件,能否真正触发抢占调度,还要看外部条件。在此之前,先来测试一下当前的功能,执行 make run LOG=trace 查看任务内部状态的变化,在几次时钟中断触发后,任务的 need_resched 被设置为 true。
第三节 触发抢占的外部条件与触发点
前面提到,在内核运行的某些阶段中,需要暂时禁用抢占,而且这种禁用有可能叠加。
为了处理叠加的情况,我们为任务增加一个计数值记录抢占禁用的情况。
pub struct Task {
... ...
preempt_disable_count: AtomicUsize,
... ...
}
impl Task {
fn new_common(id: TaskId, name: String) -> Self {
Self {
... ...
preempt_disable_count: AtomicUsize::new(0),
... ...
}
}
#[inline]
pub(crate) fn can_preempt(&self, current_disable_count: usize) -> bool {
self.preempt_disable_count.load(Ordering::Acquire) == current_disable_count
}
#[inline]
pub(crate) fn disable_preempt(&self) {
self.preempt_disable_count.fetch_add(1, Ordering::Relaxed);
}
#[inline]
pub(crate) fn enable_preempt(&self, resched: bool) {
if self.preempt_disable_count.fetch_sub(1, Ordering::Relaxed) == 1 && resched {
// If current task is pending to be preempted, do rescheduling.
Self::current_check_preempt_pending();
}
}
}关注一下 enable_preempt/disable_preempt,禁用抢占时递增,启用时递减。典型情况下,计数值是 0 时可触发抢占。
内核中直接调用 enable_preempt/disable_preempt 很容易出错,所以我们来封装一个 Guard 类型 NoPreempt 来实现对抢占的控制。
// spinlock/src/lib.rs
pub struct NoPreempt;
impl NoPreempt {
fn acquire() {
crate_interface::call_interface!(KernelGuardIf::disable_preempt);
}
fn release() {
crate_interface::call_interface!(KernelGuardIf::enable_preempt);
}
pub fn new() -> Self {
Self::acquire();
Self
}
}
impl Drop for NoPreempt {
fn drop(&mut self) {
Self::release();
}
}
// axtask/src/lib.rs
struct KernelGuardIfImpl;
#[crate_interface::impl_interface]
impl kernel_guard::KernelGuardIf for KernelGuardIfImpl {
fn disable_preempt() {
if let Some(curr) = current_may_uninit() {
curr.disable_preempt();
}
}
fn enable_preempt() {
if let Some(curr) = current_may_uninit() {
curr.enable_preempt(true);
}
}
}
pub fn current_may_uninit() -> Option<CurrentTask> {
CurrentTask::try_get()
}最后,重构一下自旋锁的实现,确保加锁时抢占是禁用状态,防止此期间任务被调度出去破坏原子性。
pub struct SpinNoIrqGuard<T> {
irq_state: usize,
data: *mut T,
}
impl<T> SpinNoIrq<T> {
#[inline(always)]
pub fn lock(&self) -> SpinNoIrqGuard<T> {
let irq_state = NoPreemptIrqSave::acquire();
SpinNoIrqGuard {
irq_state,
data: unsafe { &mut *self.data.get() },
}
}
}
impl<T> Drop for SpinNoIrqGuard<T> {
#[inline(always)]
fn drop(&mut self) {
NoPreemptIrqSave::release(self.irq_state);
}
}加锁时,调用 NoPreemptIrqSave::acquire 关抢占;解锁时,调用 NoPreemptIrqSave::release 开抢占。
这样就把抢占的控制与当前任务关联起来,下面来看一个示例:

XXX
第四节 同步原语 - Mutex
xxx
pub struct Mutex<T: ?Sized> {
wq: AxWaitQueueHandle,
owner_id: AtomicU64,
data: UnsafeCell<T>,
}
pub struct MutexGuard<'a, T: ?Sized + 'a> {
lock: &'a Mutex<T>,
data: *mut T,
}
unsafe impl<T: ?Sized + Send> Sync for Mutex<T> {}
unsafe impl<T: ?Sized + Send> Send for Mutex<T> {}
impl<T> Mutex<T> {
/// Creates a new [`Mutex`] wrapping the supplied data.
#[inline(always)]
pub const fn new(data: T) -> Self {
Self {
wq: AxWaitQueueHandle::new(),
owner_id: AtomicU64::new(0),
data: UnsafeCell::new(data),
}
}
/// Consumes this [`Mutex`] and unwraps the underlying data.
#[inline(always)]
pub fn into_inner(self) -> T {
// We know statically that there are no outstanding references to
// `self` so there's no need to lock.
let Mutex { data, .. } = self;
data.into_inner()
}
}
impl<T: ?Sized> Mutex<T> {
/// Returns `true` if the lock is currently held.
///
/// # Safety
///
/// This function provides no synchronization guarantees and so its result should be considered 'out of date'
/// the instant it is called. Do not use it for synchronization purposes. However, it may be useful as a heuristic.
#[inline(always)]
pub fn is_locked(&self) -> bool {
self.owner_id.load(Ordering::Relaxed) != 0
}
pub fn lock(&self) -> MutexGuard<T> {
let current_id = super::ax_current_task_id();
loop {
// Can fail to lock even if the spinlock is not locked. May be more efficient than `try_lock`
// when called in a loop.
match self.owner_id.compare_exchange_weak(
0,
current_id,
Ordering::Acquire,
Ordering::Relaxed,
) {
Ok(_) => break,
Err(owner_id) => {
assert_ne!(
owner_id, current_id,
"Thread({}) tried to acquire mutex it already owns.",
current_id,
);
// Wait until the lock looks unlocked before retrying
super::ax_wait_queue_wait(&self.wq, || !self.is_locked(), None);
}
}
}
MutexGuard {
lock: self,
data: unsafe { &mut *self.data.get() },
}
}
pub unsafe fn force_unlock(&self) {
let owner_id = self.owner_id.swap(0, Ordering::Release);
let current_id = super::ax_current_task_id();
assert_eq!(
owner_id, current_id,
"Thread({}) tried to release mutex it doesn't own",
current_id,
);
// wake up one waiting thread.
super::ax_wait_queue_wake(&self.wq, 1);
}
pub fn get_mut(&mut self) -> &mut T {
// We know statically that there are no other references to `self`, so
// there's no need to lock the inner mutex.
unsafe { &mut *self.data.get() }
}
}
impl<'a, T: ?Sized> Deref for MutexGuard<'a, T> {
type Target = T;
#[inline(always)]
fn deref(&self) -> &T {
// We know statically that only we are referencing data
unsafe { &*self.data }
}
}
impl<'a, T: ?Sized> DerefMut for MutexGuard<'a, T> {
#[inline(always)]
fn deref_mut(&mut self) -> &mut T {
// We know statically that only we are referencing data
unsafe { &mut *self.data }
}
}
impl<'a, T: ?Sized> Drop for MutexGuard<'a, T> {
/// The dropping of the [`MutexGuard`] will release the lock it was created from.
fn drop(&mut self) {
unsafe { self.lock.force_unlock() }
}
}xxx
pub fn ax_wait_queue_wait(
wq: &AxWaitQueueHandle,
until_condition: impl Fn() -> bool,
timeout: Option<Duration>,
) -> bool {
if let Some(_dur) = timeout {
unimplemented!();
}
if timeout.is_some() {
panic!("ax_wait_queue_wait: the `timeout` argument is ignored without the `irq` feature");
}
wq.0.wait_until(until_condition);
false
}
pub fn ax_wait_queue_wake(wq: &AxWaitQueueHandle, count: u32) {
if count == u32::MAX {
wq.0.notify_all(true);
} else {
for _ in 0..count {
wq.0.notify_one(true);
}
}
}xxx
附录A 内核布局文件 LDS
OUTPUT_ARCH(riscv)
BASE_ADDRESS = 0x80200000;
ENTRY(_start)
SECTIONS
{
. = BASE_ADDRESS;
_skernel = .;
.text : ALIGN(4K) {
_stext = .;
*(.text.boot)
*(.text .text.*)
. = ALIGN(4K);
_etext = .;
}
.rodata : ALIGN(4K) {
_srodata = .;
*(.rodata .rodata.*)
*(.srodata .srodata.*)
*(.sdata2 .sdata2.*)
. = ALIGN(4K);
_erodata = .;
}
.data : ALIGN(4K) {
_sdata = .;
*(.data .data.*)
*(.sdata .sdata.*)
*(.got .got.*)
. = ALIGN(4K);
_edata = .;
}
.bss : ALIGN(4K) {
boot_stack = .;
. += 256K;
boot_stack_top = .;
_sbss = .;
boot_page_table = .;
. += 4K;
boot_page_table_end = .;
*(.bss .bss.*)
*(.sbss .sbss.*)
*(COMMON)
. = ALIGN(4K);
_ebss = .;
}
_ekernel = .;
/DISCARD/ : {
*(.comment) *(.gnu*) *(.note*) *(.eh_frame*)
}
}
注:启用分页之后,BASE_ADDRESS = 0xffffffc080200000;
附录B 内核编译文件Makefile
# General options
ARCH ?= riscv64
TARGET := riscv64gc-unknown-none-elf
SMP ?= 1
LOG ?= warn
FEATURES ?=
# Utility definitions and functions
GREEN_C := \033[92;1m
CYAN_C := \033[96;1m
YELLOW_C := \033[93;1m
GRAY_C := \033[90m
WHITE_C := \033[37m
END_C := \033[0m
QEMU := qemu-system-$(ARCH)
OBJDUMP ?= rust-objdump -d --print-imm-hex --x86-asm-syntax=intel
OBJCOPY ?= rust-objcopy --binary-architecture=$(ARCH)
# App options
A ?= axorigin
APP ?= $(A)
APP_NAME := $(shell basename $(APP))
LD_SCRIPT := $(CURDIR)/linker.lds
OUT_DIR ?= target/$(TARGET)/release
OUT_ELF := $(OUT_DIR)/$(APP_NAME)
OUT_BIN := $(OUT_DIR)/$(APP_NAME).bin
ifeq ($(filter $(MAKECMDGOALS),test),) # not run `cargo test`
RUSTFLAGS := -C link-arg=-T$(LD_SCRIPT) -C link-arg=-no-pie
export RUSTFLAGS
endif
export LOG
all: build
build: $(OUT_BIN)
disasm: build
$(OBJDUMP) $(OUT_ELF) | less
run: build justrun
justrun:
@printf " $(CYAN_C)Running$(END_C) on qemu...\n"
$(QEMU) -m 128M -smp $(SMP) -machine virt \
-bios default -kernel $(OUT_BIN) -nographic \
-D qemu.log -d in_asm
$(OUT_BIN): $(OUT_ELF)
$(OBJCOPY) $(OUT_ELF) --strip-all -O binary $@
$(OUT_ELF): FORCE
@printf " $(GREEN_C)Building$(END_C) App: $(APP_NAME), Arch: riscv64, Platform: qemu-virt, App type: rust\n"
cargo build --manifest-path $(APP)/Cargo.toml --release \
--target $(TARGET) --target-dir $(CURDIR)/target $(FEATURES)
clean:
@rm -rf ./target
@rm -f ./qemu.log
test:
cargo test --workspace --exclude "axorigin" -- --nocapture
FORCE:
@:
.PHONY: all build disasm run justrun test clean FORCE
注:建立axhal组件后,把 linker.lds 挪到该组件目录之下,LD_SCRIPT := $(CURDIR)/axhal/linker.lds。